# 实例分割
# 简介
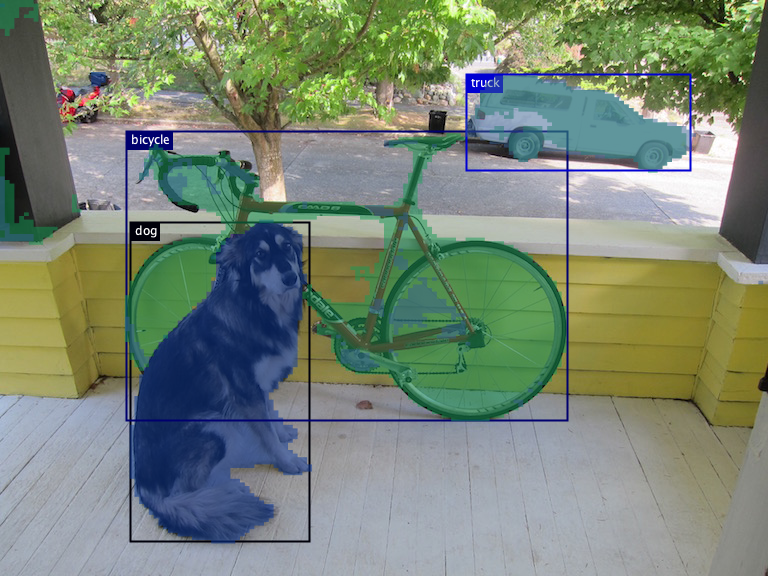
实例分割比对象检测更进一步,包括识别图像中的各个对象并将它们与图像的其余部分分割开来。 实例分割模型的输出是一组掩码或轮廓,它们勾勒出图像中每个对象,以及每个对象的类别标签和置信度分数。 当您不仅需要知道对象在图像中的位置,还需要知道它们的精确形状时,实例分割非常有用。
与其他任务的区别
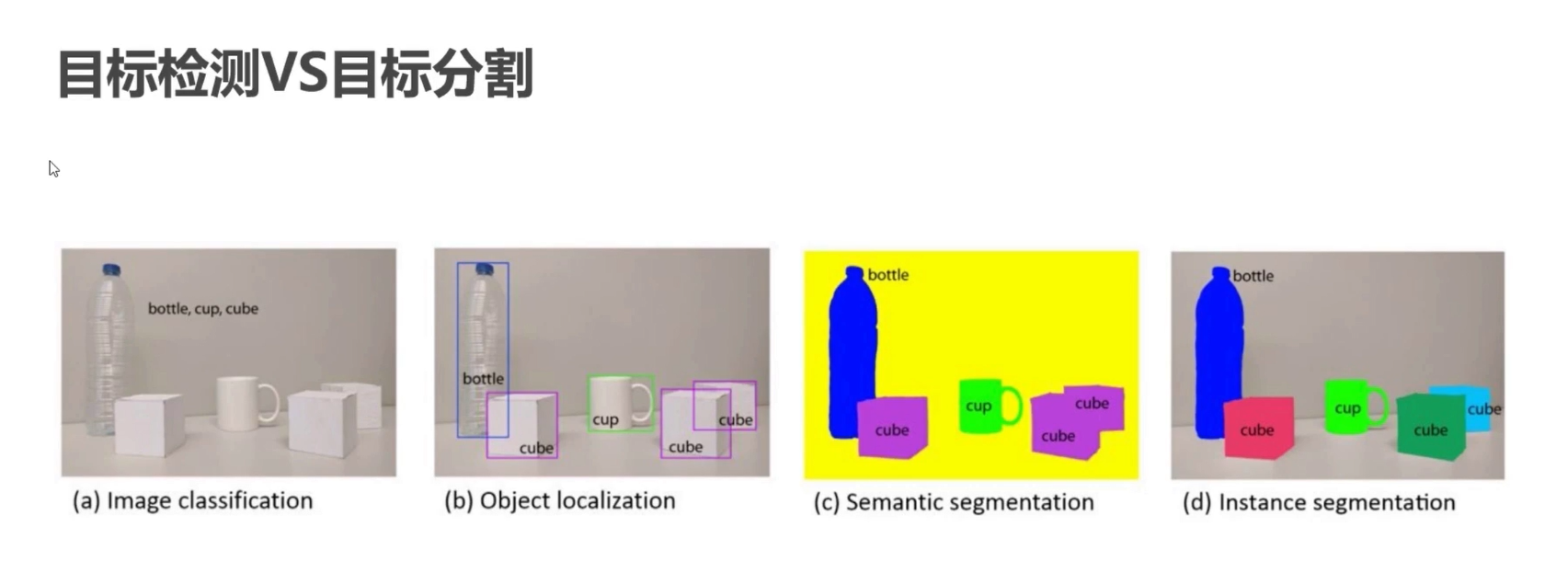
目标检测(Object Detection) 通过边界框(bounding box)定位并分类目标,但不能精确到像素级,只能大致框出目标区域。
语义分割(Semantic Segmentation) 逐像素分类,能够精确划分目标形状,但无法区分同类别的不同个体。
实例分割(Instance Segmentation) 结合了目标检测和实例分割的优势,既能像实例分割那样进行像素级划分,又能像目标检测那样区分不同个体。
# 安装
# Maven
在项目的 pom.xml 中添加以下依赖,详细引入方式参考 Maven 引入。
如需引入全部功能,请使用 【不推荐 ❌】 all 模块。
<dependency>
<groupId>cn.smartjavaai</groupId>
<artifactId>vision</artifactId>
<version>1.1.1</version>
</dependency>
# 获取实例分割模型
InstanceSegModelConfig config = new InstanceSegModelConfig();
config.setModelEnum(InstanceSegModelEnum.SEG_YOLO11N_ONNX);
config.setModelPath("/Users/wenjie/Documents/develop/model/vision/instance/yolo11n-seg-onnx/yolo11n-seg.onnx");
config.setThreshold(0.5f);
InstanceSegModel instanceSegModel = InstanceSegModelFactory.getInstance().getModel(config);
# InstanceSegModelConfig参数说明
| 字段名称 | 字段类型 | 默认值 | 说明 |
|---|---|---|---|
| modelEnum | InstanceSegModelEnum | 无 | 实例分割模型枚举 |
| modelPath | String | 模型路径 | |
| allowedClasses | List<String> | 允许的分类列表 | |
| threshold | double | 0.5 | 置信度阈值,分数低于这个值的结果将被过滤掉。值越高越严格,越低越宽松 |
| device | DeviceEnum | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 0 | gpu设备ID 当device为GPU时生效 |
| predictorPoolSize | int | 默认为cpu核心数 | 模型预测器线程池大小 |
| customParams | Map<String, Object> | 无 | 个性化配置(按模型类型动态解析) |
# 实例分割模型
| 模型名称 | 引擎 | 模型简介 | 模型开源网站 |
|---|---|---|---|
| YOLOV8-SEG | OnnxRuntime | Ultralytics在COCO 数据集 上训练的模型 | Github (opens new window) |
| YOLOV11-SEG | OnnxRuntime | Ultralytics在COCO 数据集 上训练的模型 | Github (opens new window) |
| Mask R-CNN | MXNet | Mask R-CNN 是一种在目标检测基础上,同时为每个物体生成像素级分割区域的深度学习模型 | 无 |
⚠️ 注意 :
1、不同模型支持的类别可能不一样,具体可查看模型目录下的 synset.txt 文件,其中列出了该模型支持的全部物体名称。
2、每个模型均支持加载自训练模型文件。用户只需在路径中指定自训练的模型文件,并在 synset.txt 中存放对应的类别信息,即可完成模型的自定义部署。
# InstanceSegModel API 方法说明
# 实例分割
Image图片源请查看文档Image使用说明
R<DetectionResponse> detect(Image image);
DetectedObjects detectCore(Image image);
# DetectionResponse字段说明
- 返回并非json格式,仅用于字段讲解
{
"detectionInfoList": [ //检测信息列表
{
"detectionRectangle": { //矩形框
"height": 174, // 矩形高度
"width": 147, // 矩形宽度
"x": 275, // 左上角横坐标
"y": 143 // 左上角纵坐标
},
"instanceSegInfo": { //目标掩码信息
"className": "person", //类别
"mask":[[0,0,0,0...],[0,0,0,0...]]
},
"score": 0.8118719 //检测结果置信度分数
}
]
}
# 检测并绘制结果
该接口支持对图像进行检测,并将检测结果绘制在图像上,同时返回检测结果信息。
- 保存绘制后的图片到指定路径,检测结果通过
DetectionResponse返回。
R<DetectionResponse> detectAndDraw(String imagePath, String outputPath);
- 支持直接输入
Image对象进行检测,检测结果通过DetectionResponse返回。
可以通过DetectionResponse中的drawnImage获取绘制后的Image对象。
R<DetectionResponse> detectAndDraw(Image image);
# 使用说明
imagePath:待检测图像的文件路径。outputPath:绘制检测结果后图像的保存路径。image:待检测的Image对象。- 返回的
DetectionResponse包含检测框信息及绘制后的图像(drawnImage),方便后续处理或展示。
# 模型下载
百度网盘:https://pan.baidu.com/s/14tNVK1fCH7Hvzkb8XNBSnQ?pwd=1234 提取码: 1234