# 目标检测模型训练
作为 Java 程序员,我们在使用自有数据集训练目标检测模型时,常常会遇到一个难题:目前主流的目标检测模型训练基本都依赖 Python 语言。这对只熟悉 Java 的开发者来说,无疑增加了学习成本和使用难度。
虽然基于 DJL(Deep Java Library)可以实现无需编写 Python 代码、甚至不必安装 Python 环境即可训练模型,极大降低了门槛。但 DJL 官方目前提供的预训练模型主要是早期的 SSD 和 YOLO,这些模型的准确率和速度已不及最新的检测算法。
如果想自行实现最新的目标检测模型,又需要深入理解每个模型的神经网络架构,难度较大,门槛较高。
综合考虑,我认为比较实用的折中方案是:使用 PyTorch 或 TensorFlow 的 API 来训练模型,训练过程可以借助现成的工具和配置,不必手写复杂代码;然后再通过我们开发的 SmartJavaAI(基于 DJL 封装)来做模型的推理部署。这样既能充分利用主流深度学习框架的训练优势,又能让 Java 程序员轻松进行模型推理。
Java 开发者看到这里,请不要被“Python”吓到,其实训练过程相当简单,并不需要你写任何 Python 代码。我会提供详细的、零基础也能跟着做的完整教程,帮助你轻松完成模型训练。
注意事项:
1、本教程基于 Windows + CPU 环境 进行训练,其他平台(如 Linux 或 GPU)教程将后续补充。
2、在本教程中用到的所有资源,我都已整理好并上传至百度网盘,下载链接如下:https://pan.baidu.com/s/1k8CYtwX8qVTEC593nlePoQ?pwd=xzm9 提取码: xzm9
3、训练过程中,有任何问题可以加微信入群讨论:deng775747758
# 一、安装python环境
# 1. 安装 Anaconda3
你可以从清华大学开源软件镜像站下载 Anaconda3 的安装包:
🔗 Anaconda 镜像下载地址 (opens new window)
请根据你电脑的操作系统选择对应的安装版本。建议选择最新版。安装过程非常简单,一路点击 Next 即可完成。
我本地安装的版本为:
Anaconda3-5.3.1-Windows-x86_64.exe
安装完成后,打开 Anaconda Prompt(可以通过点击 Windows 开始菜单搜索Anaconda Prompt并打开):
如果命令行前显示 (base),说明 Anaconda 已成功安装并初始化:
部分用户打开prompt窗口没有显示base,而是显示的Anaconda路径,这个时候需要检查一下安装的版本,重新安装最新版本
# 2. 修改 pip 安装源为国内镜像
由于默认的 pip源在国外,下载速度较慢,我们建议将 pip 源修改为国内镜像,例如清华大学镜像源。
# 步骤如下:
打开文件管理器,在地址栏输入:
%APPDATA%按回车后会跳转到路径:
C:\Users\用户名\AppData\Roaming在该目录下新建一个名为
pip的文件夹。在
pip文件夹中创建一个名为pip.ini的配置文件。编辑
pip.ini文件,添加以下内容(使用清华源):
[global]
timeout = 6000
index-url = https://pypi.tuna.tsinghua.edu.cn/simple
[install]
trusted-host = pypi.tuna.tsinghua.edu.cn
✅ 提示:
1、你也可以将源替换为其他国内镜像站点,如阿里云、豆瓣等。
2、我们提供的网盘链接里也包含此文件,可以直接下载使用
# 3. 创建并激活虚拟环境
在进行项目开发时,推荐使用虚拟环境来隔离不同项目的依赖库。下面我们将通过 Anaconda 创建一个新的 Python 虚拟环境。
打开 Anaconda Prompt,执行以下命令:
创建虚拟环境
conda create -n yolov12 python=3.11
🔍 说明:
yolov12是环境名称,你可以根据需要自定义;python=3.11表示该环境使用的 Python 版本。
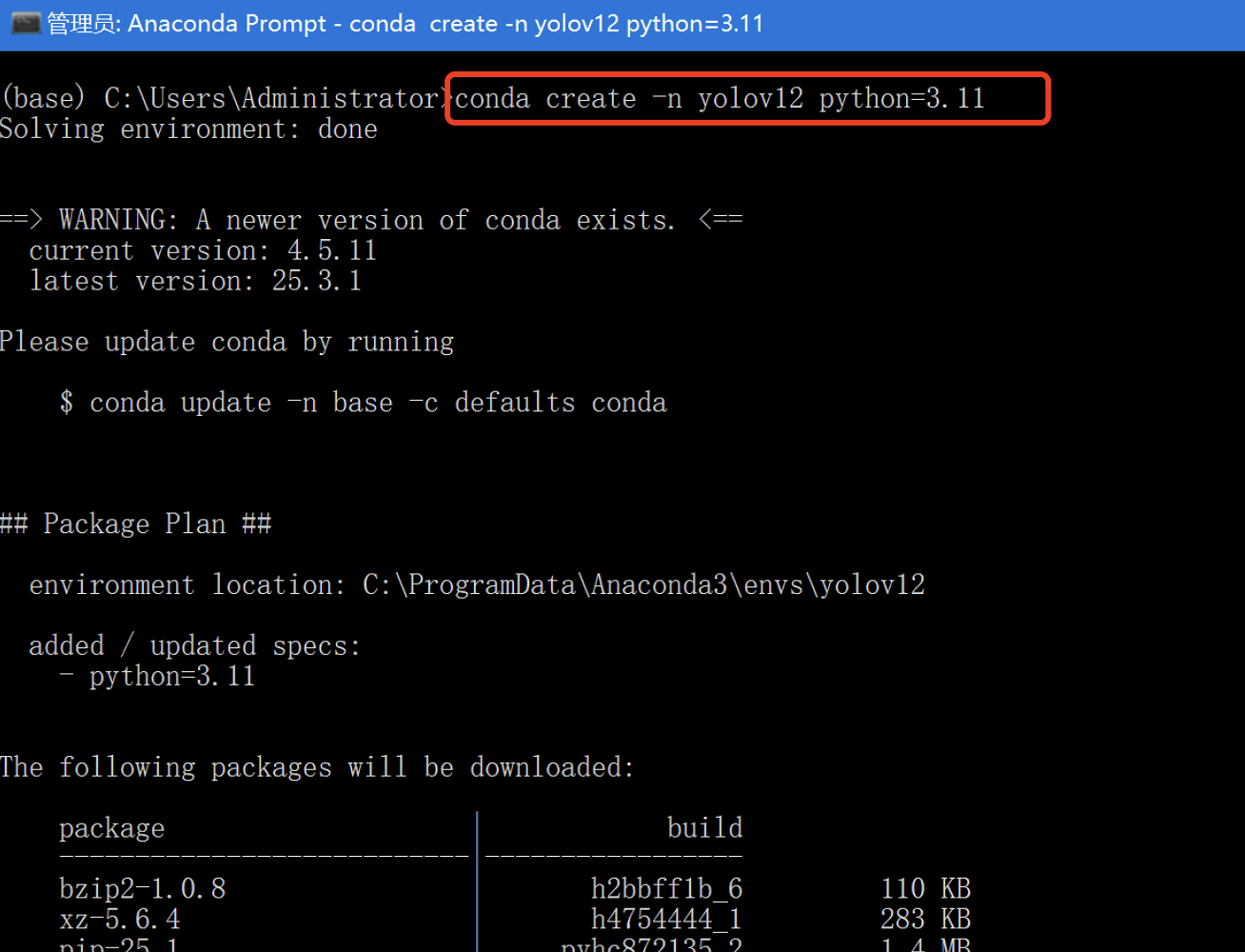
输入 y 并按回车继续安装:
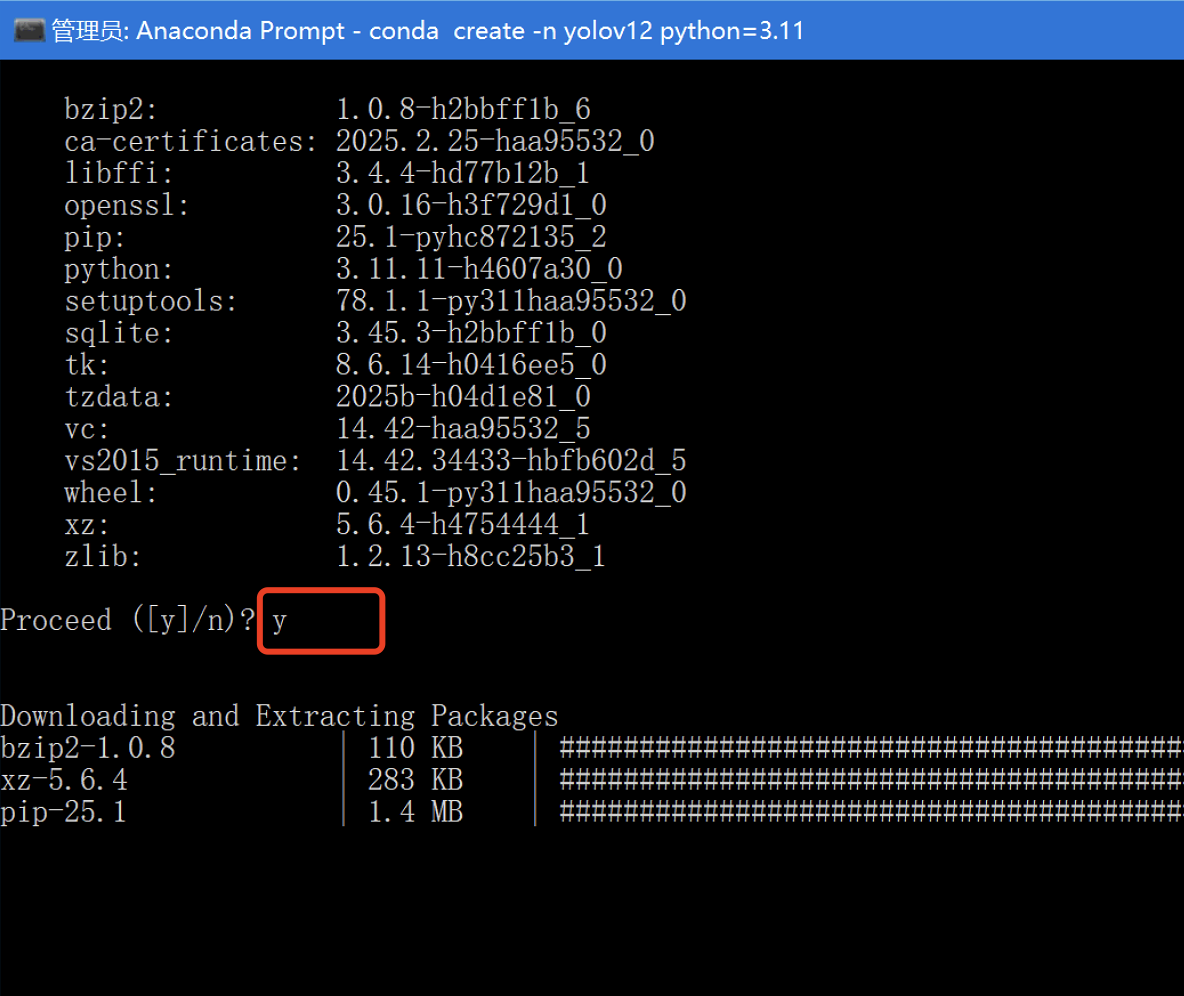
等待安装完成后,你会看到如下提示界面:
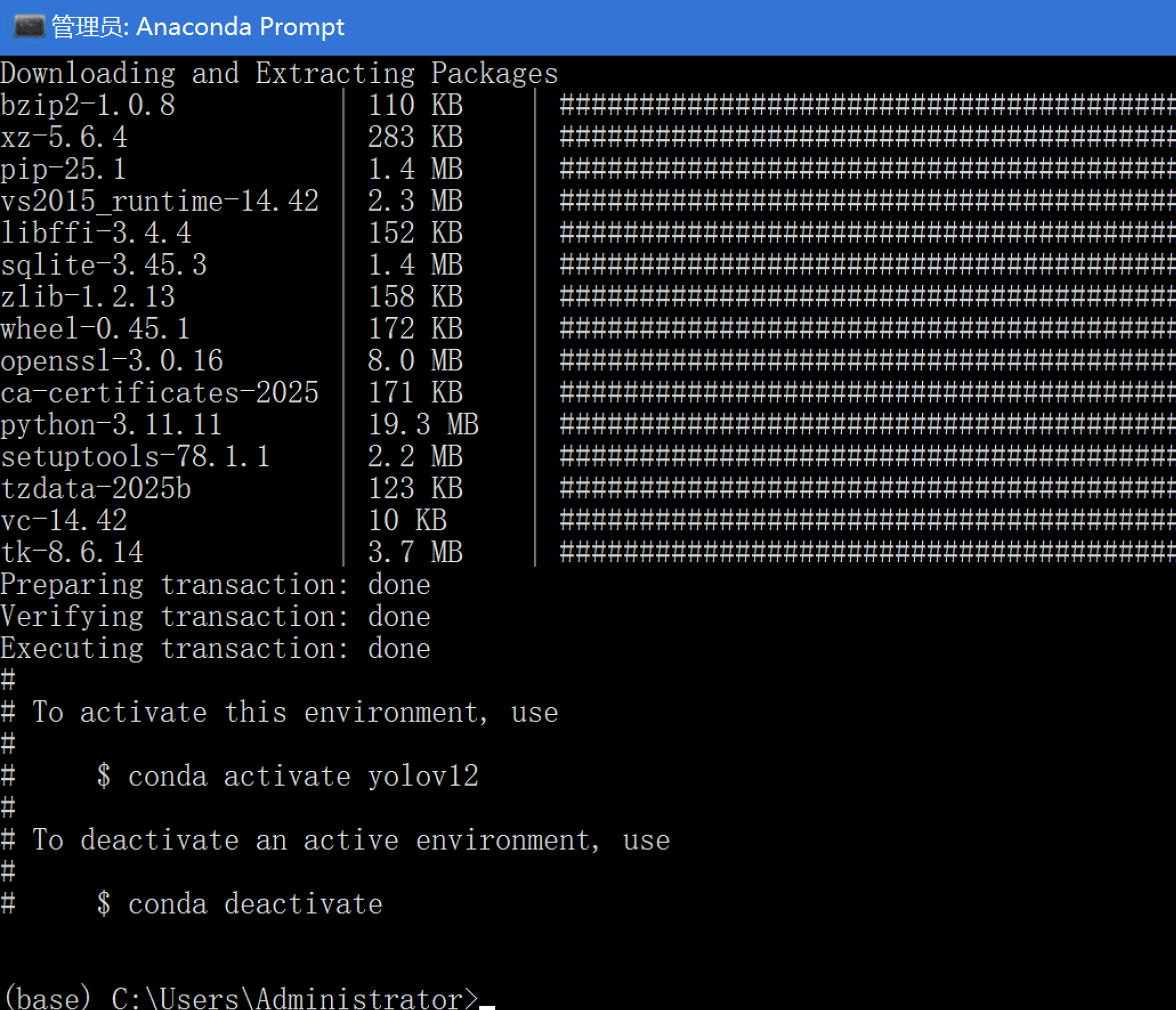
激活虚拟环境
conda activate yolov12
激活后,命令行前会显示当前环境名 (yolov12),表示已成功进入该虚拟环境:

✅ 恭喜!你现在已成功安装 Anaconda,并创建了一个独立的 Python 虚拟环境。
# 二、安装yolov12
# 1. 下载 YOLOv12
你可以通过以下方式将项目克隆或解压到本地:
- 方式一:使用 Git 拉取代码(推荐)
git clone https://github.com/sunsmarterjie/yolov12.git
方式二:手动下载压缩包并解压
GitHub 官方地址:
https://github.com/sunsmarterjie/yolov12 (opens new window)国内镜像地址(如无法访问 GitHub):
https://gitee.com/dengwenjie/yolov12 (opens new window)
# 2. 安装依赖库
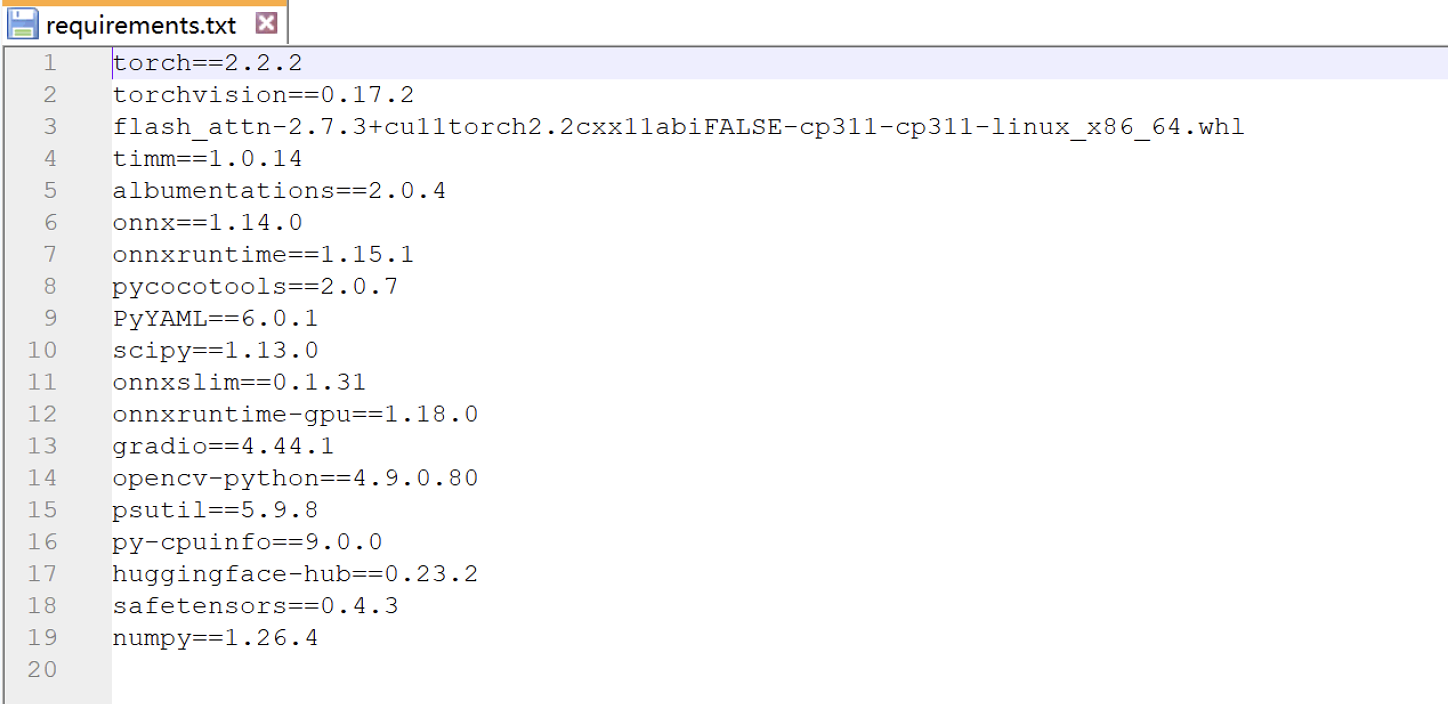
进入 yolov12-main 项目的根目录,打开 requirements.txt 文件。该文件列出了所有需要安装的 Python 包。
前2个包为了提高安装成功率,我们教大家手动安装,第3个包只有用GPU才需要,CPU使用不需要安装。
# (1)下载依赖包
请根据你的 Python 版本(我们的Python版本是3.11)选择对应的 wheel 文件进行下载(也可以从我们提供的网盘下载):
PyTorch
- 文件名:torch-2.2.2+cpu-cp311-cp311-win_amd64.whl
- 下载地址:
https://download.pytorch.org/whl/cpu/torch-2.2.2%2Bcpu-cp311-cp311-win_amd64.whl (opens new window)
TorchVision
- 文件名:torchvision-0.17.2+cpu-cp311-cp311-win_amd64.whl
- 下载地址:
https://download.pytorch.org/whl/cpu/torchvision-0.17.2%2Bcpu-cp311-cp311-win_amd64.whl (opens new window)
Torchaudio
- 文件名:torchaudio-2.2.2+cpu-cp311-cp311-win_amd64.whl
- 下载地址:
https://download.pytorch.org/whl/cpu/torchaudio-2.2.2%2Bcpu-cp311-cp311-win_amd64.whl (opens new window)
⚠️ 注意:这些包适用于 CPU 版本,且部分版本与 Python 版本有关,请确保与你当前环境匹配。
# (2)手动安装依赖
将上述三个 .whl 文件统一存放到一个目录中,例如:D:\yolo\lib\
然后在 Anaconda Prompt 或命令行中切换到该目录,并依次执行以下命令进行安装:
pip install torch-2.2.2+cpu-cp311-cp311-win_amd64.whl
pip install torchvision-0.17.2+cpu-cp311-cp311-win_amd64.whl
pip install torchaudio-2.2.2+cpu-cp311-cp311-win_amd64.whl
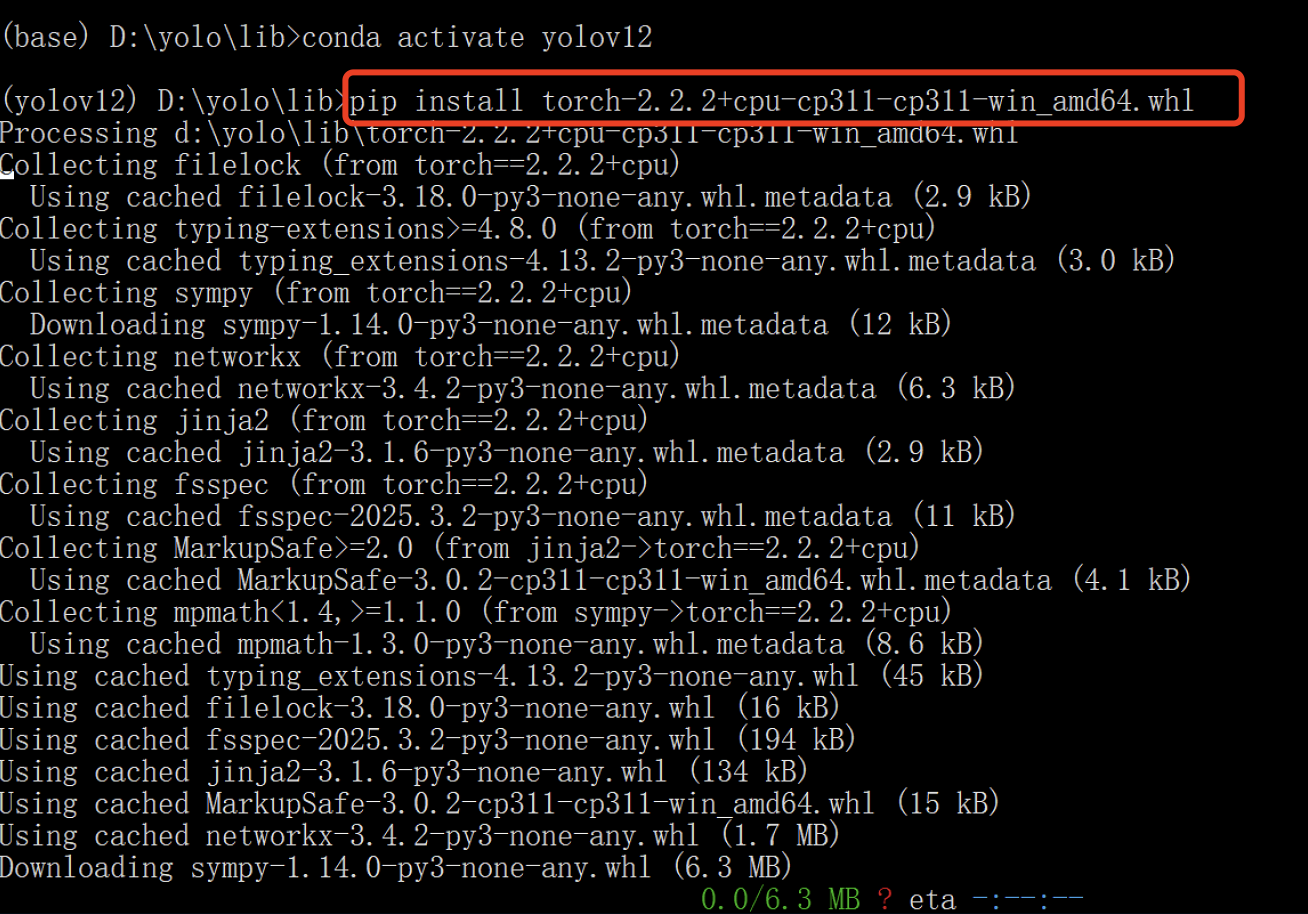
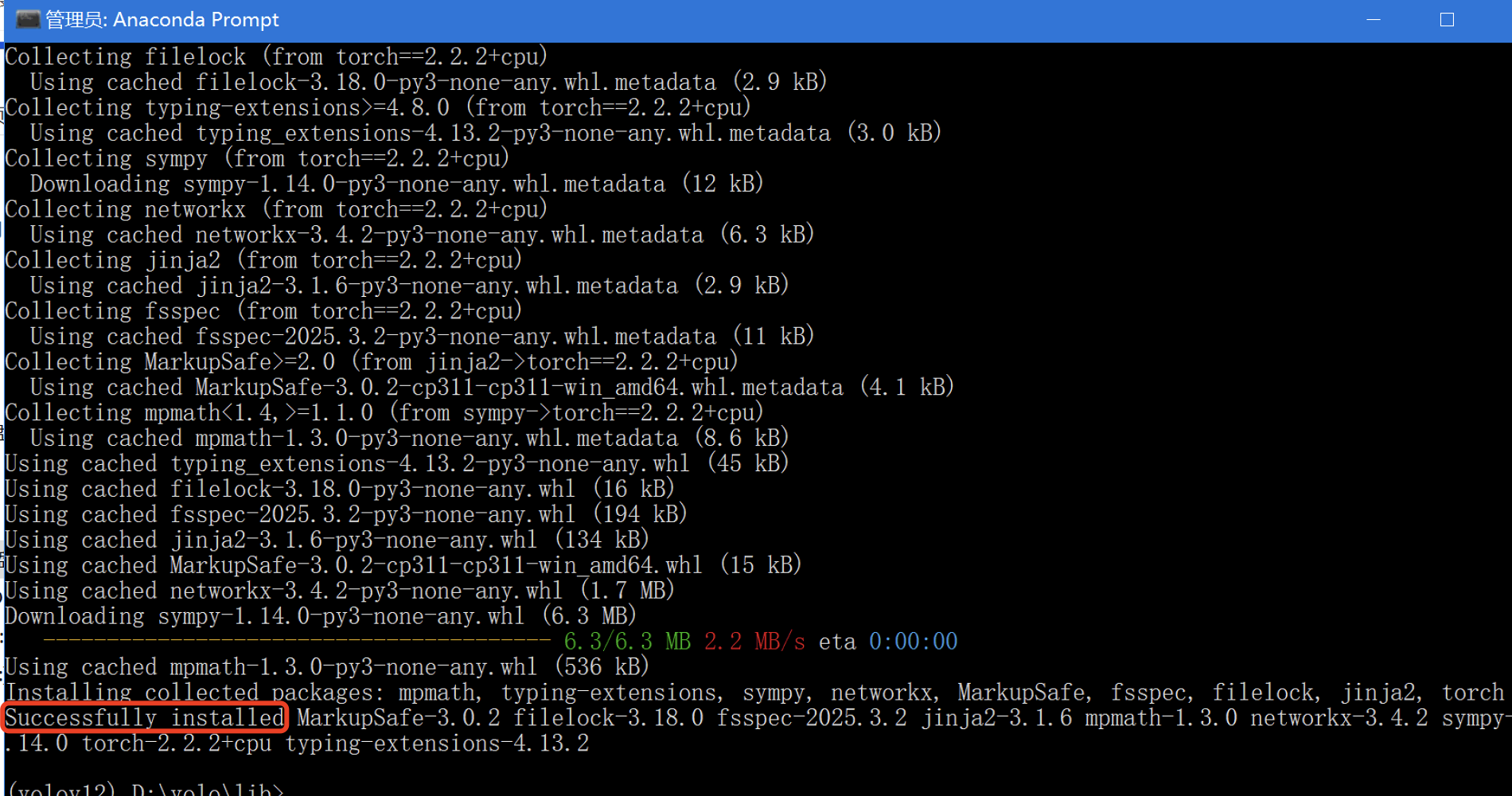
如果输出中出现类似以下信息,说明安装成功:
Successfully installed ...
如果出现红色报错信息,则表示安装失败。
# 3. 安装 requirements.txt 中的依赖库
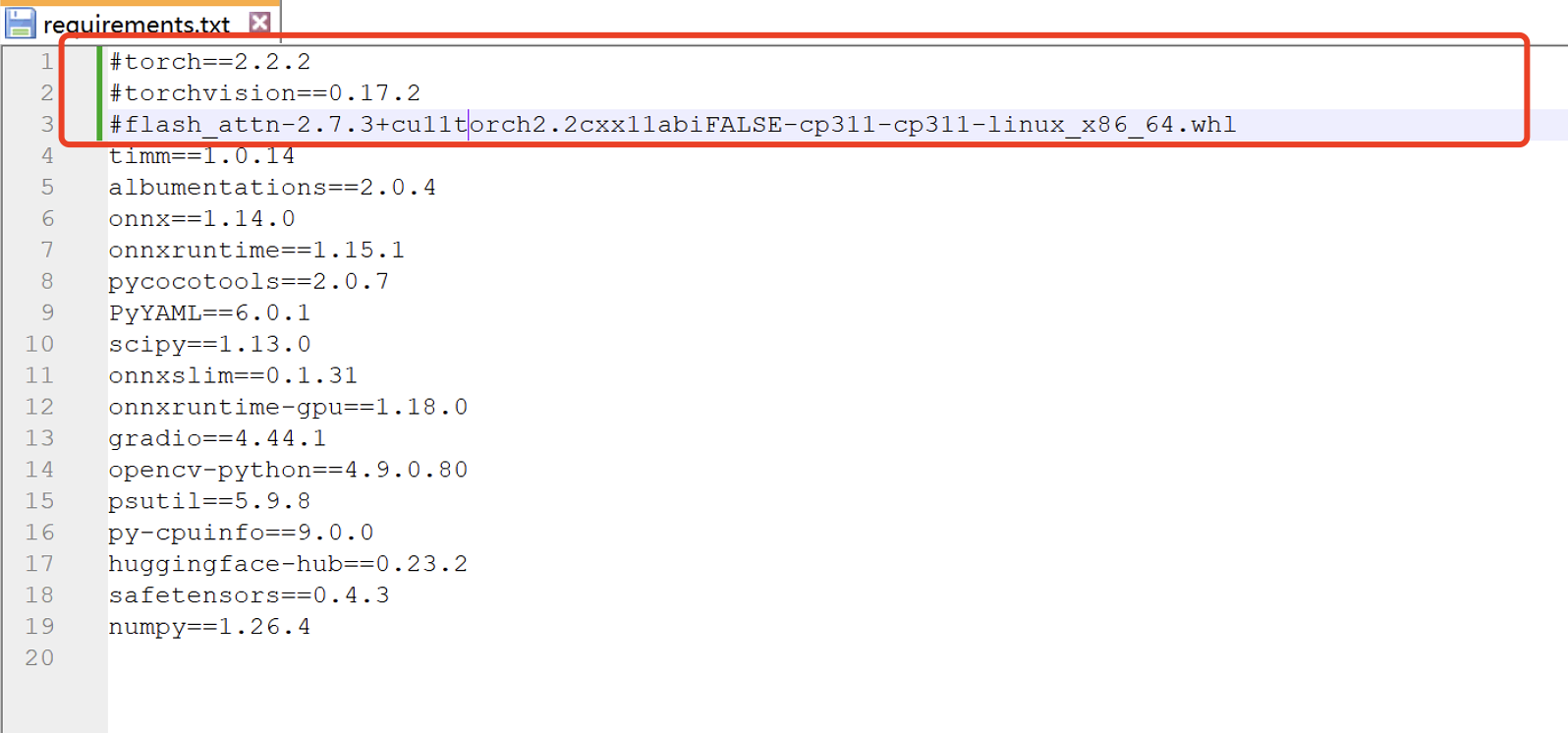
在安装 requirements.txt 中的依赖之前,请务必注释掉前三行。因为我们已经手动安装了前两个依赖库(torch 和 torchvision),第三个依赖库仅在使用 NVIDIA 显卡并支持 CUDA 的环境下才需要安装。
你可以通过在每行前加 # 来注释掉这三行:
接着,在打开的 Anaconda Prompt 窗口中,进入 yolov12-main 项目的根目录,执行以下命令来安装剩余依赖:
pip install -r requirements.txt
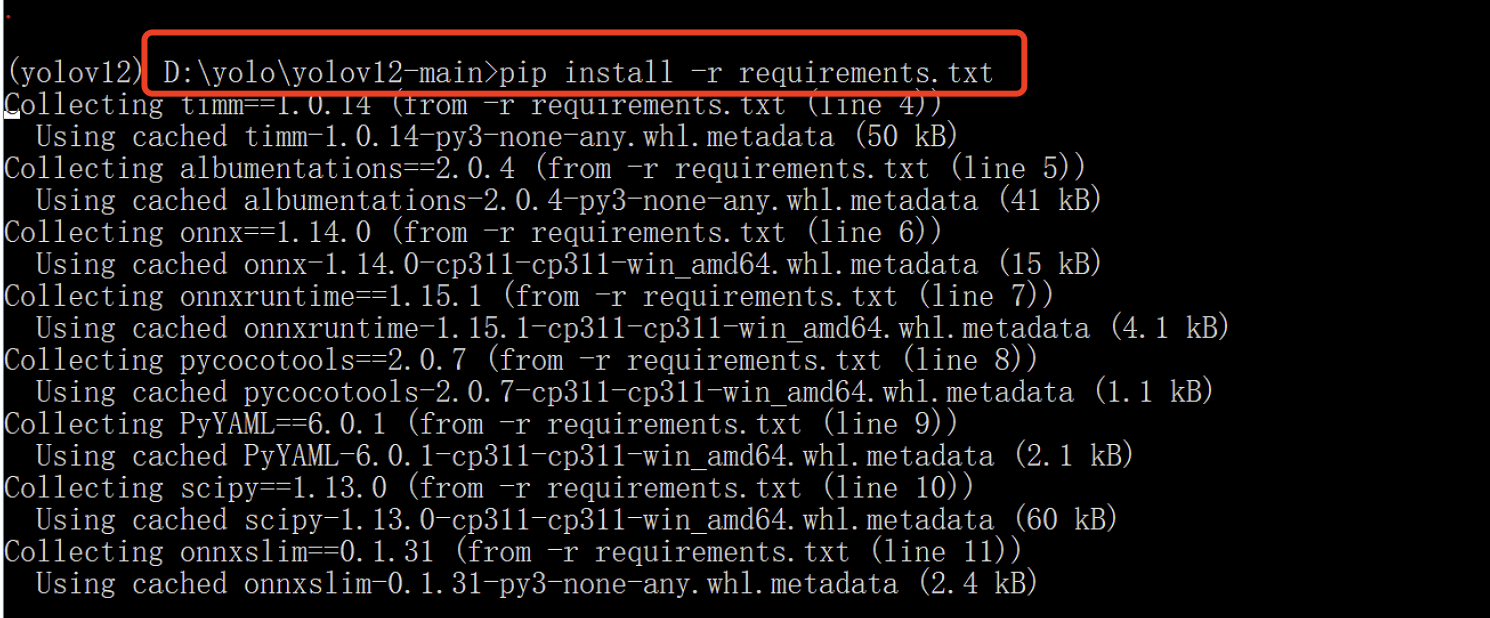
如果看到类似如下输出,则表示安装成功:
Successfully installed xxxxx
# 4. 下载模型文件
YOLOv12 的 GitHub 官方页面提供了预训练模型的下载链接。如果你无法访问 GitHub,也可以通过我们提供的网盘链接进行下载。
请将下载好的模型文件放置在项目yolov12-main根目录中,以便后续训练或推理任务使用。
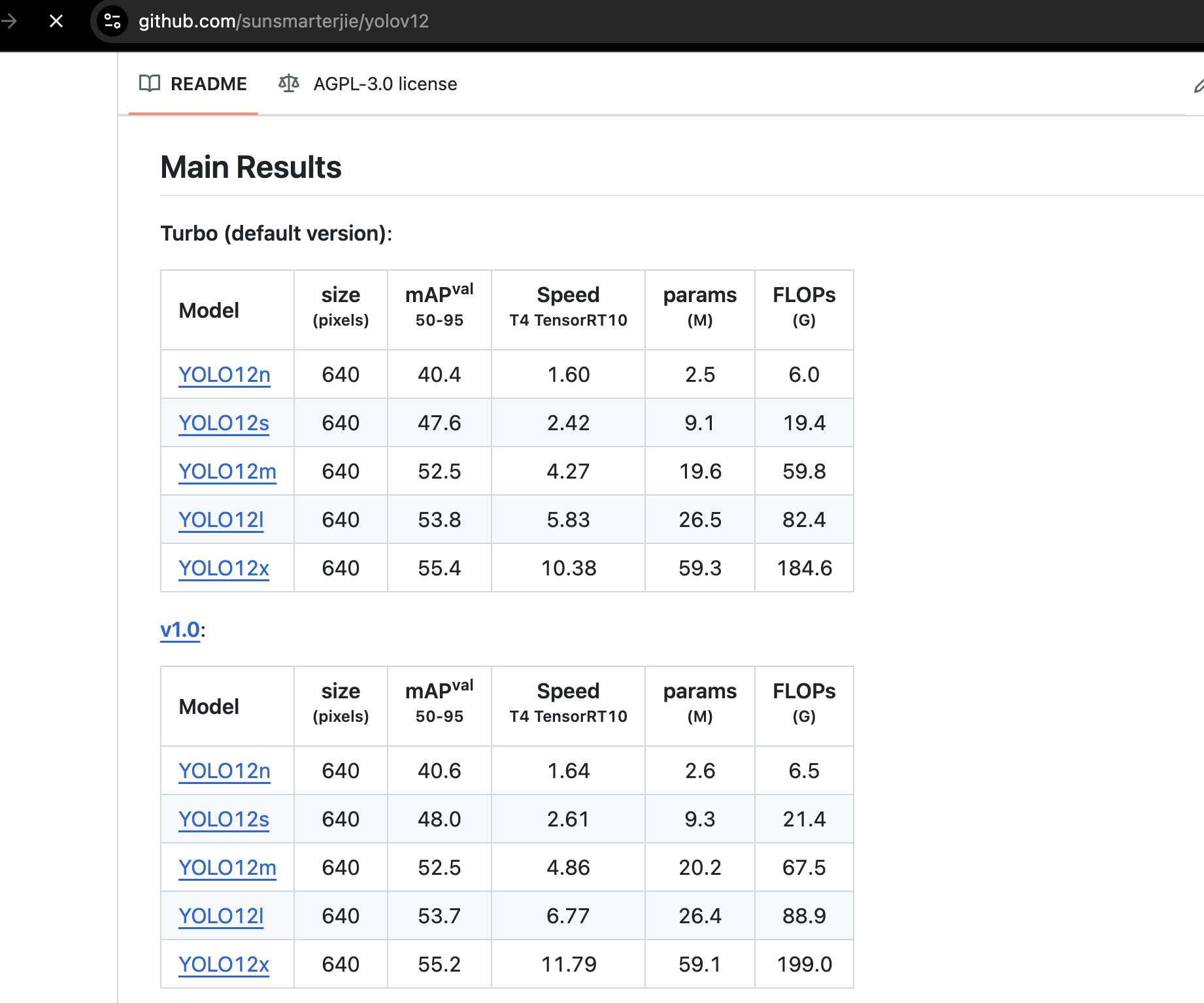
官网模型参数讲解
| 字段 | 含义 |
|---|---|
| Model | 模型的具体版本(n/s/m/l/x)表示从最小到最大,参数量逐渐增多,性能也逐步增强 |
| size (pixels) | 输入图像的尺寸(通常是方形,640×640) |
| mAPval 50‒95 | 检测精度(mean Average Precision),值越高说明识别越准确,范围是 0~100 |
| Speed (T4 TensorRT10) | 使用 NVIDIA T4 GPU(TensorRT 加速)下的推理速度,单位应该是毫秒或帧每秒(根据项目而定) |
| params (M) | 模型的参数量,单位是百万(M),数字越大模型越复杂、越重 |
| FLOPs (G) | 浮点运算次数(计算复杂度),单位是 GFLOPs,越大代表计算量越大(对 CPU/GPU 要求越高) |
各模型适应场景,可以按需下载
| 模型名 | 适用场景 | 特点 |
|---|---|---|
| YOLO12n (nano) | 移动端、低功耗设备 | 模型非常小,速度快,精度一般 |
| YOLO12s (small) | 实时性要求高的轻量部署 | 精度比 nano 高一点,依然很轻 |
| YOLO12m (medium) | 平衡性能和速度 | 精度明显提升,适合中型项目 |
| YOLO12l (large) | 精度优先 | 参数量大,推理慢,精度高 |
| YOLO12x (extra large) | 离线处理、精度最高 | 超大模型,计算资源消耗最大,但精度最好 |
# 5. 运行官方网页
为了启动 YOLOv12 的官方网页应用,请按照以下步骤操作:
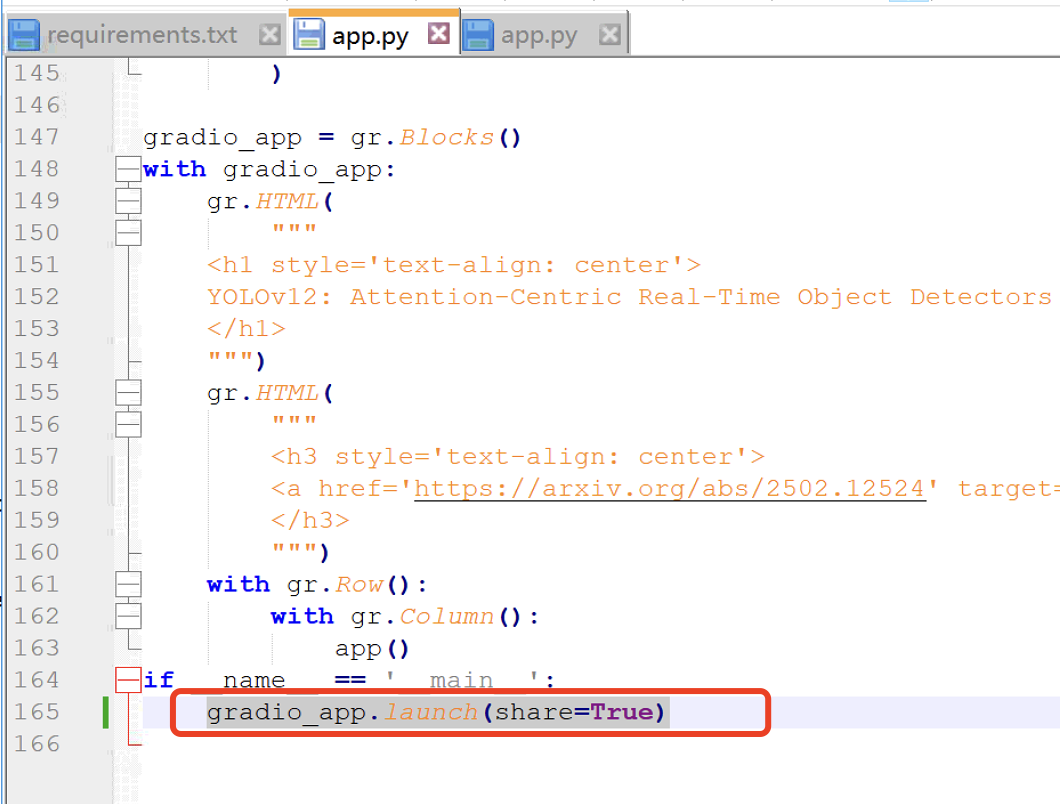
# 修改 app.py 文件
进入 yolov12 根目录,找到并编辑 app.py 文件。将文件的最后一行修改为:
gradio_app.launch(share=True)
# 安装依赖库
在运行应用之前,还需要安装两个额外的依赖库:
pip install thop
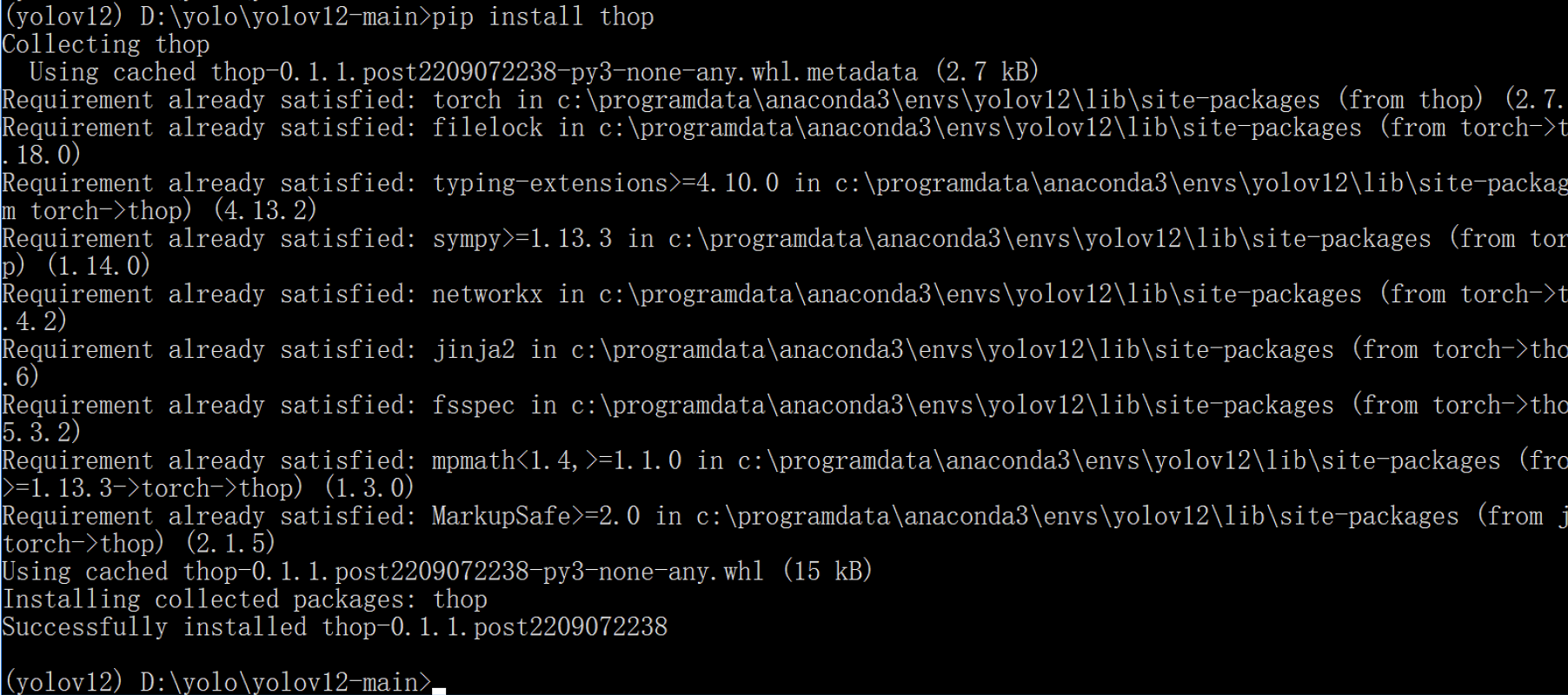
pip install pydantic==2.10.6
由于每个人的电脑环境可能不同,安装完这两个库后仍有可能出现缺少依赖库的报错。如果出现类似“No module named 'xxx‘ ”的错误提示,只需根据提示安装对应的依赖库即可。
# 启动应用
在 Anaconda Prompt 窗口中,确保你已经进入了 yolov12 的根目录,然后执行以下命令来启动应用:
python app.py
如果缺少 thop 库,可能会出现错误提示:
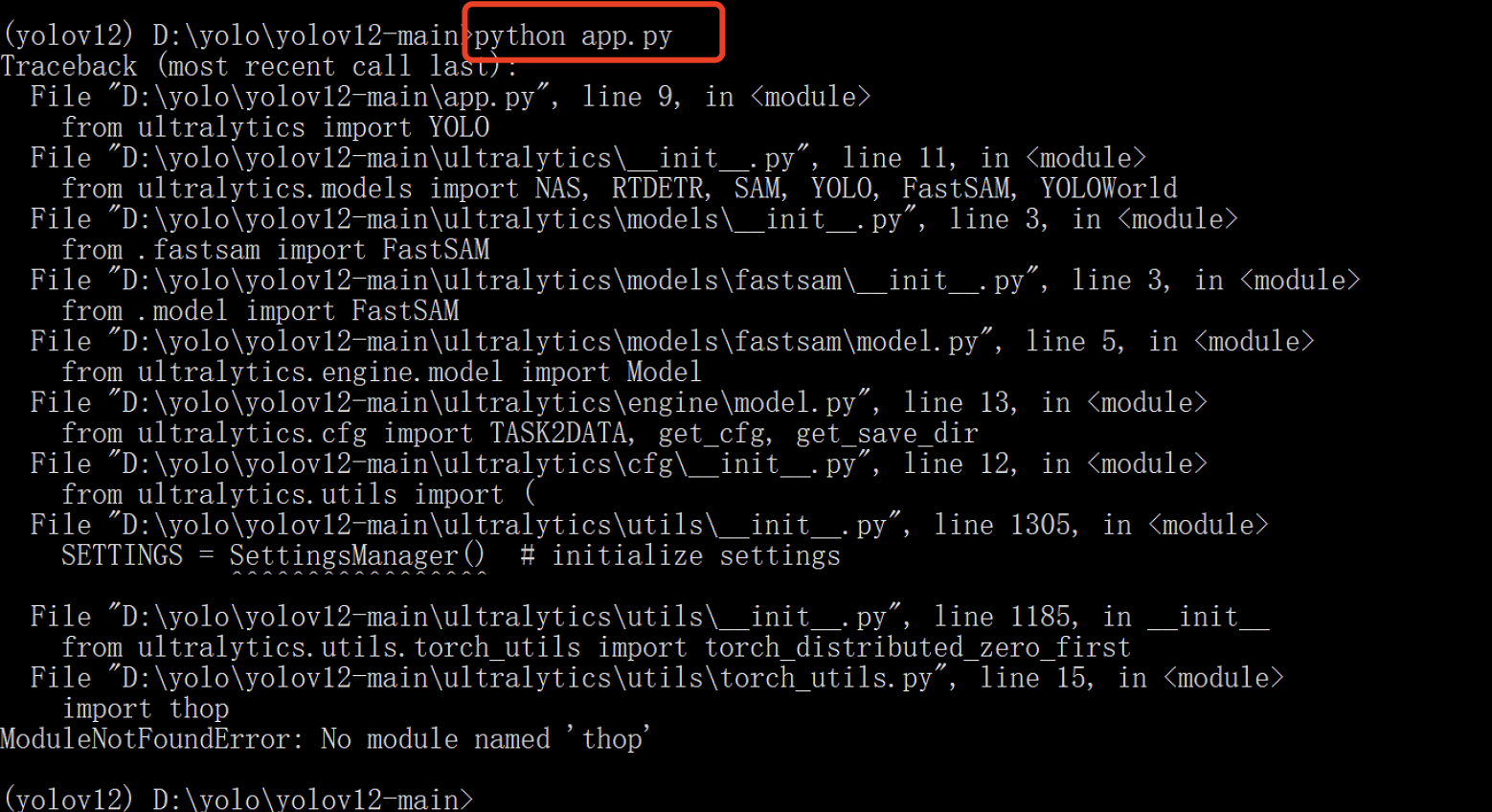
如果没有正确安装 pydantic==2.10.6,也可能会遇到如下错误:
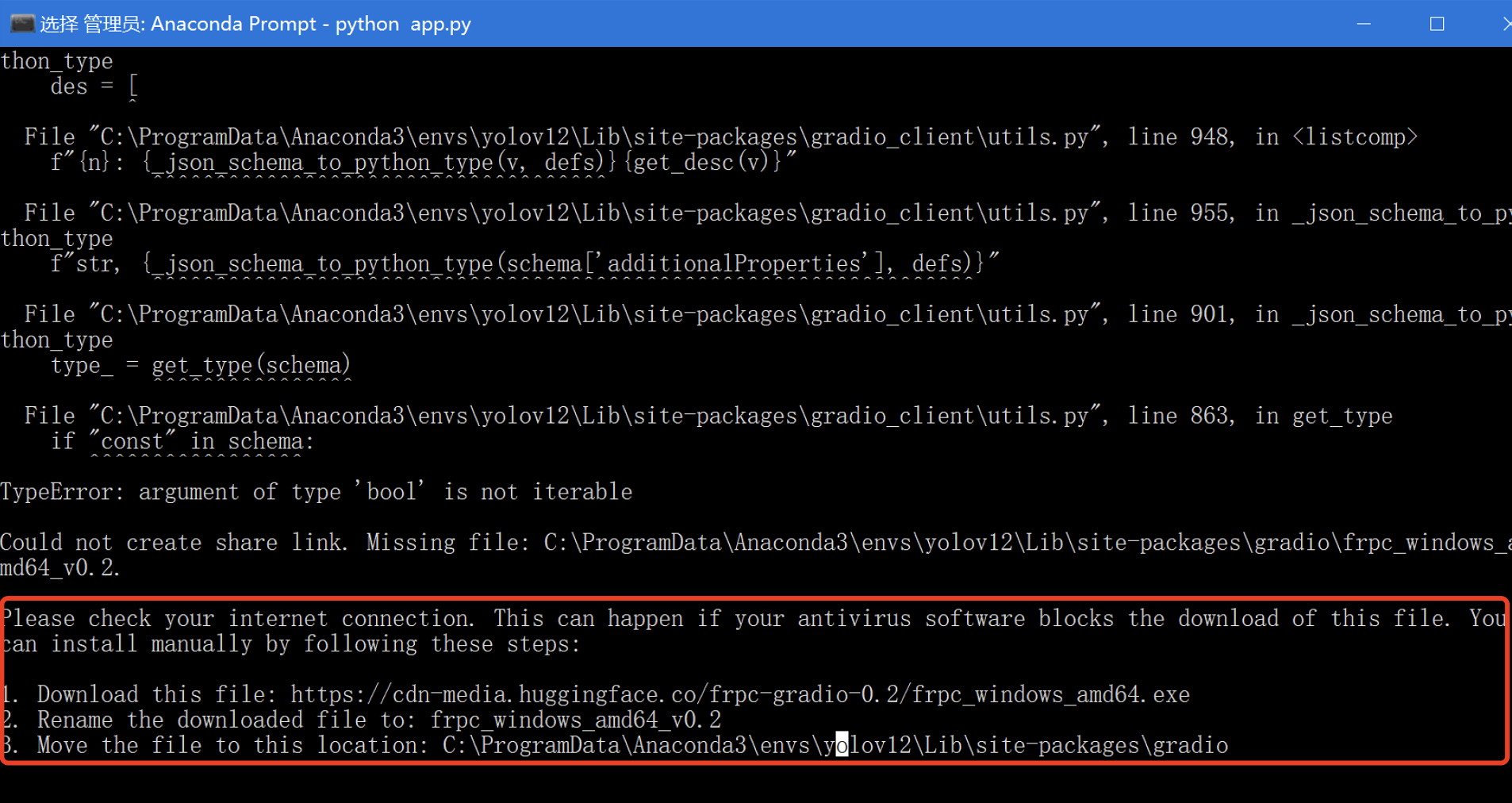
成功启动后的界面如下图所示:
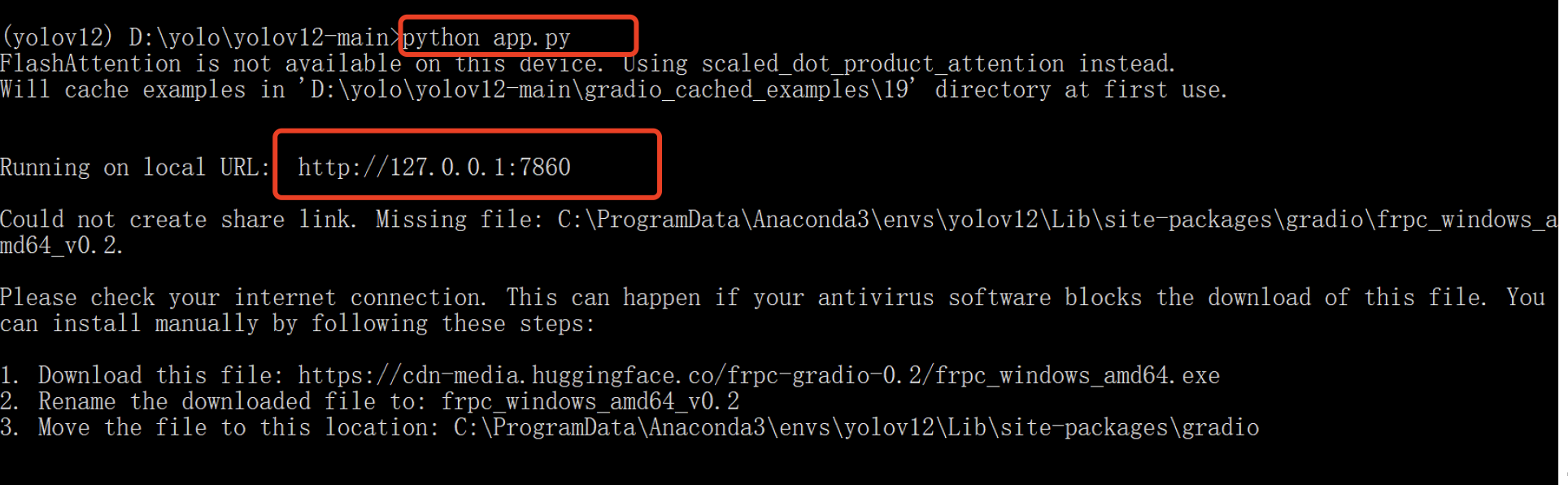
# 访问 Web 应用
根据控制台输出的日志信息,在浏览器中打开链接(例如:http://127.0.0.1:7860)。请注意实际端口号可能有所不同。
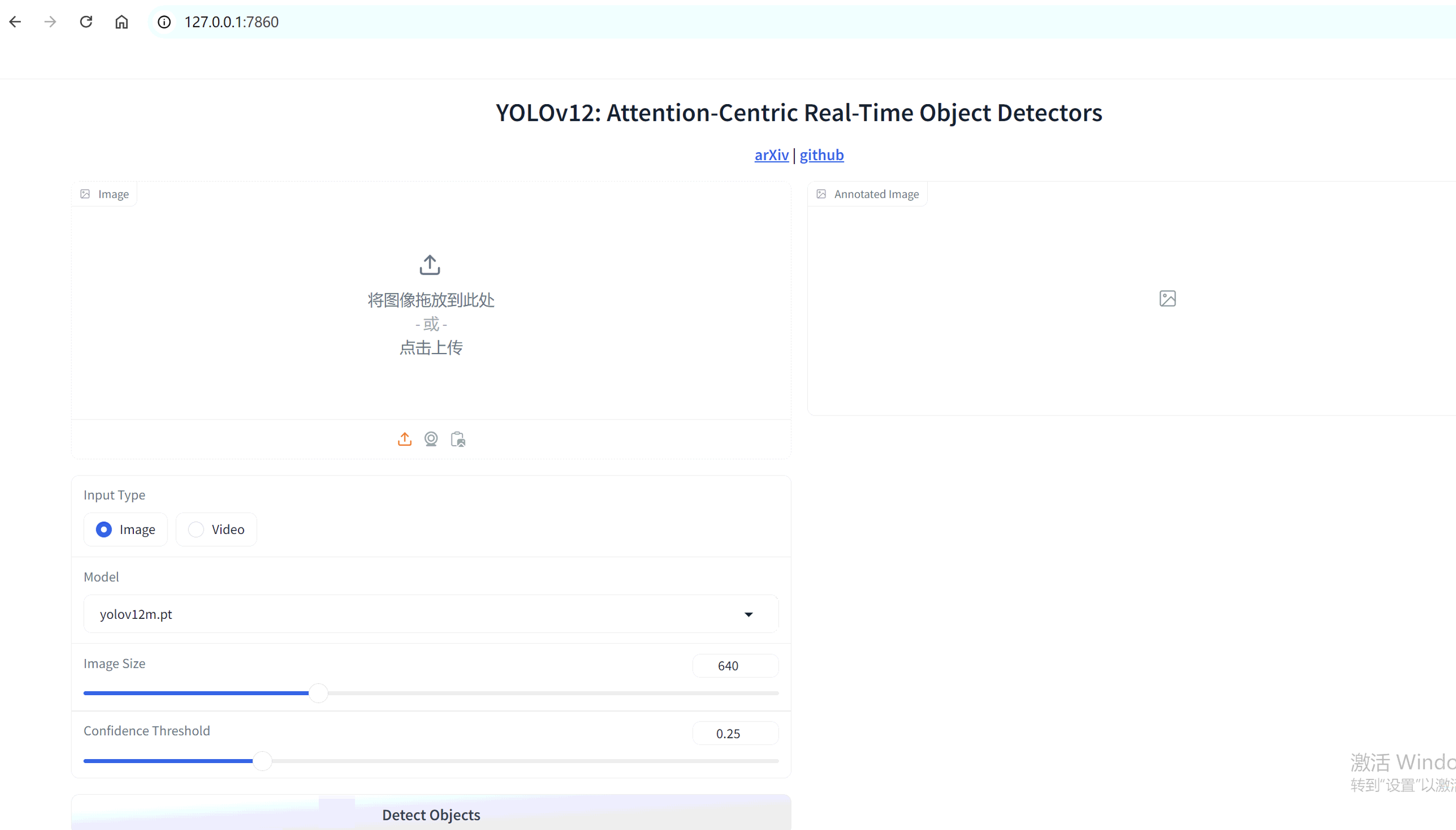
# 准备模型文件
在运行前,请确保已提前下载好模型文件,并放置于 yolov12 根目录中。在网页应用中上传图片后,在 Model 中选择相应的模型文件,点击“Detect Objects”按钮即可开始检测。若未提前下载模型,系统会自动下载,但速度较慢。
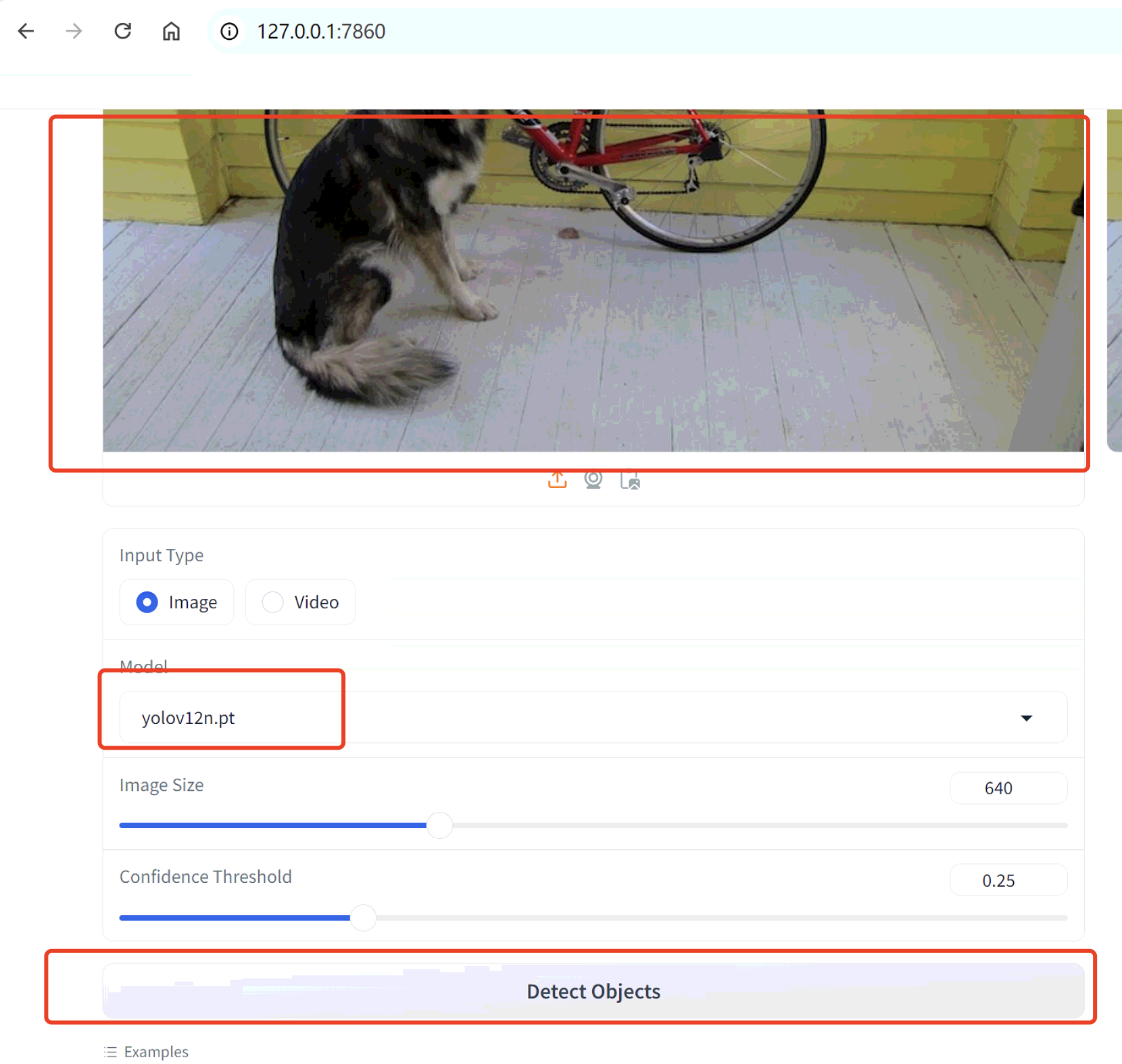
检测效果展示:
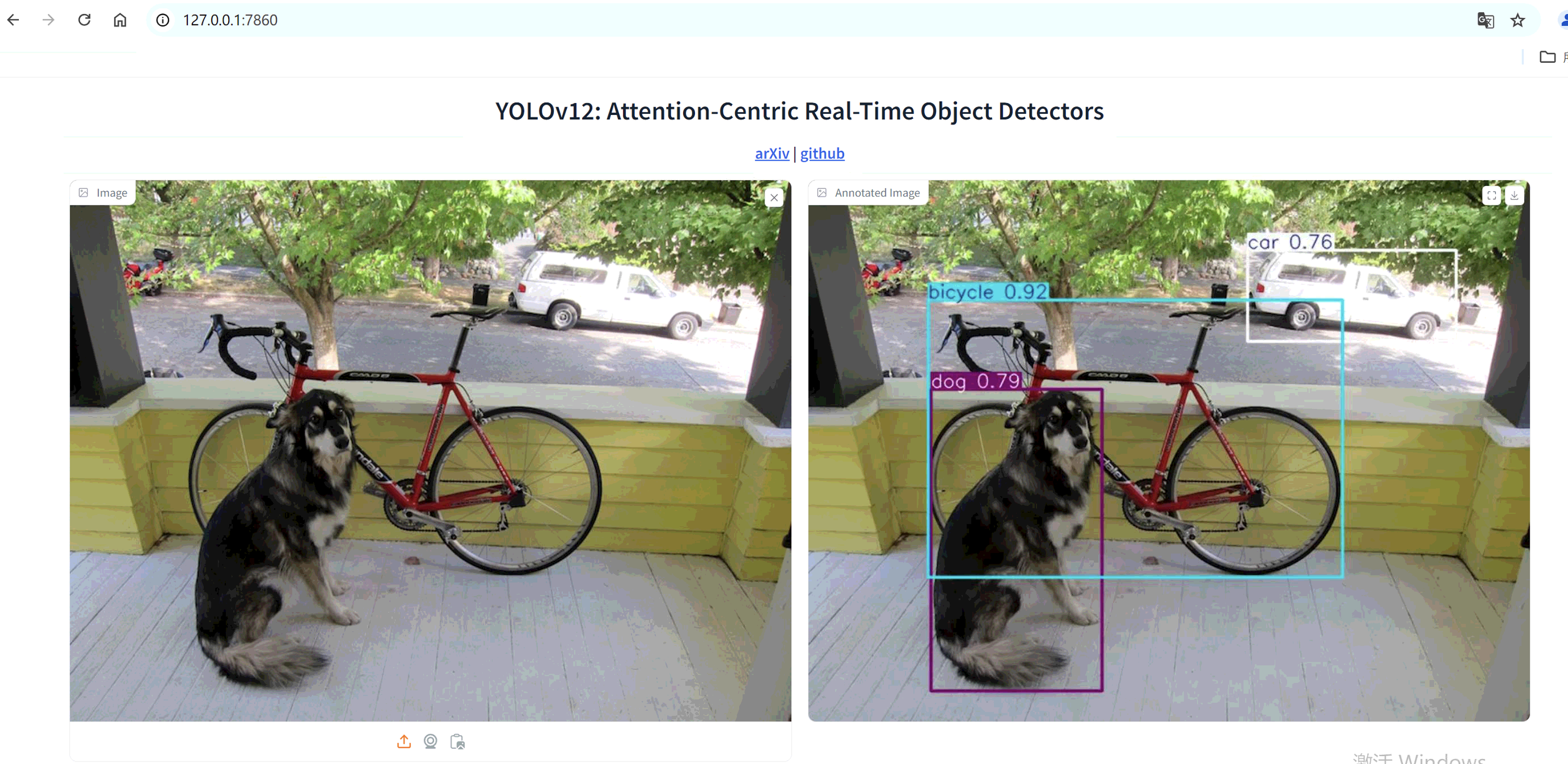
至此,YOLOv12 已经安装完毕,接下来可以进行模型训练。
# 三、训练模型
# 1. 数据标注
在进行模型训练之前,我们需要对图像数据进行标注。本教程将使用开源工具 LabelImg 来完成数据标注工作。
# 下载 LabelImg
LabelImg 是一个轻量级且易于使用的图像标注工具,支持 Windows、Mac 和 Linux 系统。
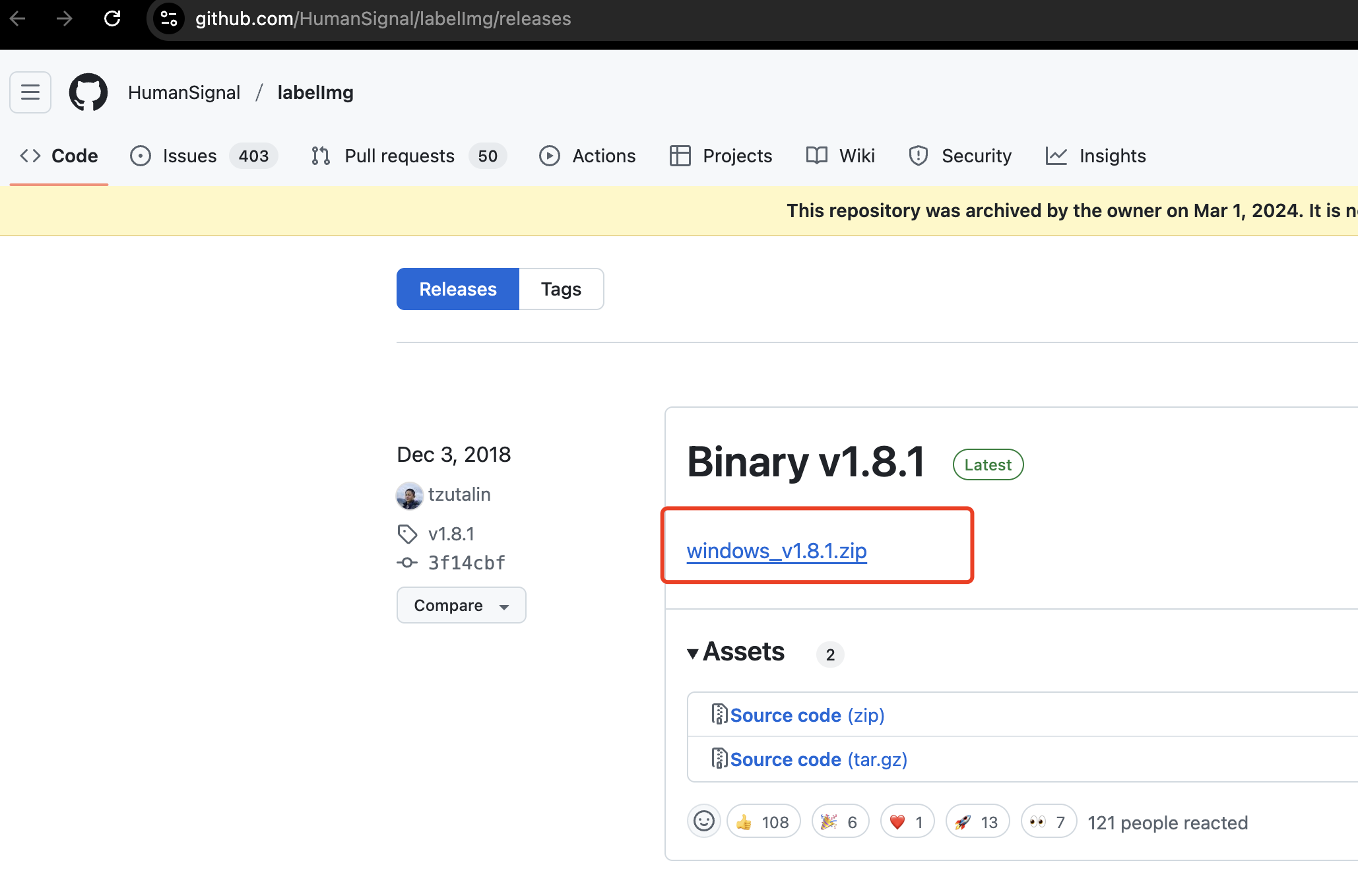
下载地址:
https://github.com/HumanSignal/labelImg/releases (opens new window)
我们下载 windows_v1.8.1.zip 版本(Windows 用户)
解压后即可使用。
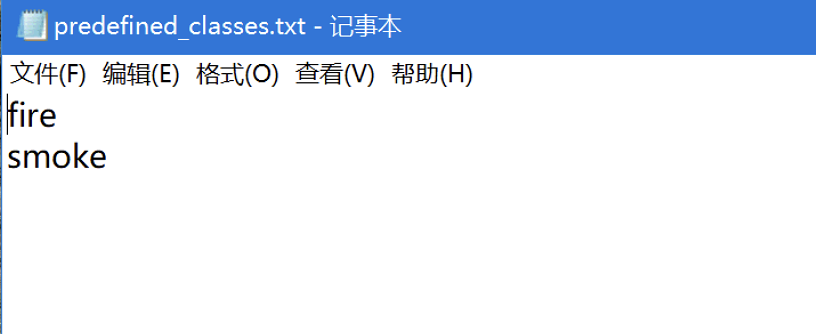
# 设置分类类别
打开 windows_v1.8.1\data 文件夹中的 predefined_classes.txt 文件。
该文件定义了预设的类别,每一行代表一个类别。你可以删除原有内容并添加你自己的类别。
示例:我们这里添加两个类别 ——
火焰和烟雾
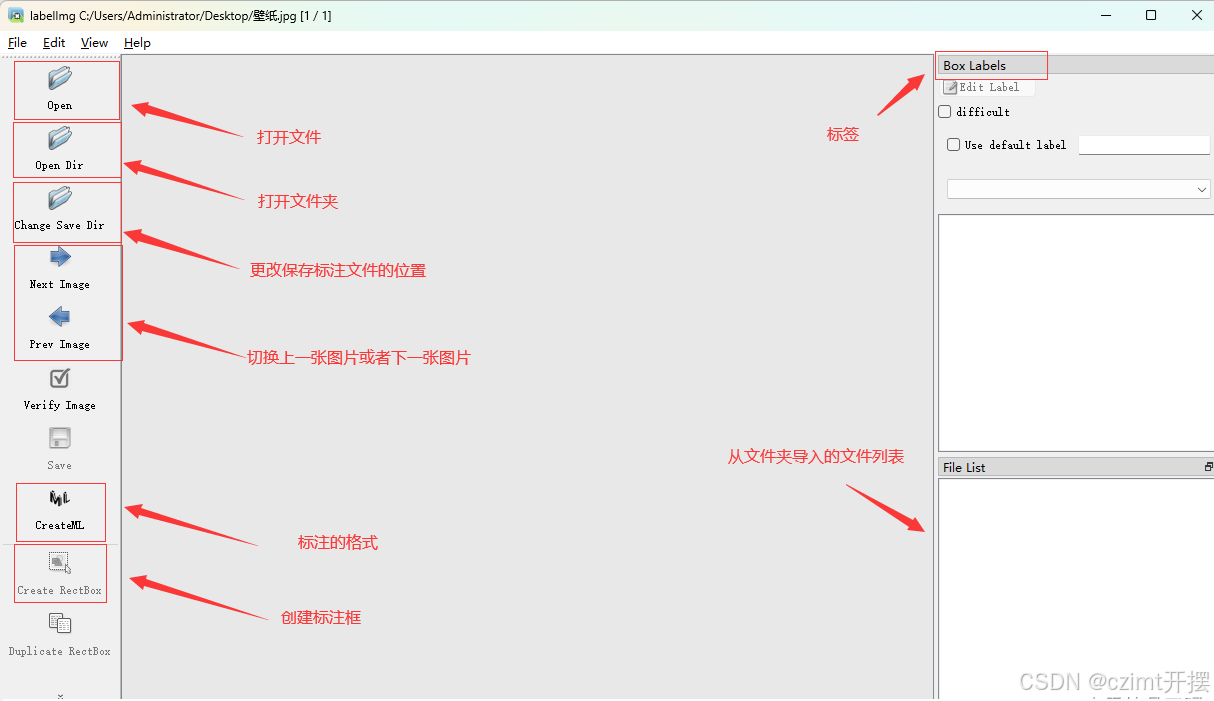
# 启动软件
直接双击 .exe 文件运行 LabelImg,界面如下所示:
# 创建目录结构
建议创建如下两个文件夹:
images:存放需要标注的原始图片labels:存放生成的标注文件(.txt)
本教程使用的是一个公开的 火焰与烟雾数据集,你也可以使用自己的数据集。
将压缩包Fire and Smoke Dataset解压到images文件夹中即可开始标注。
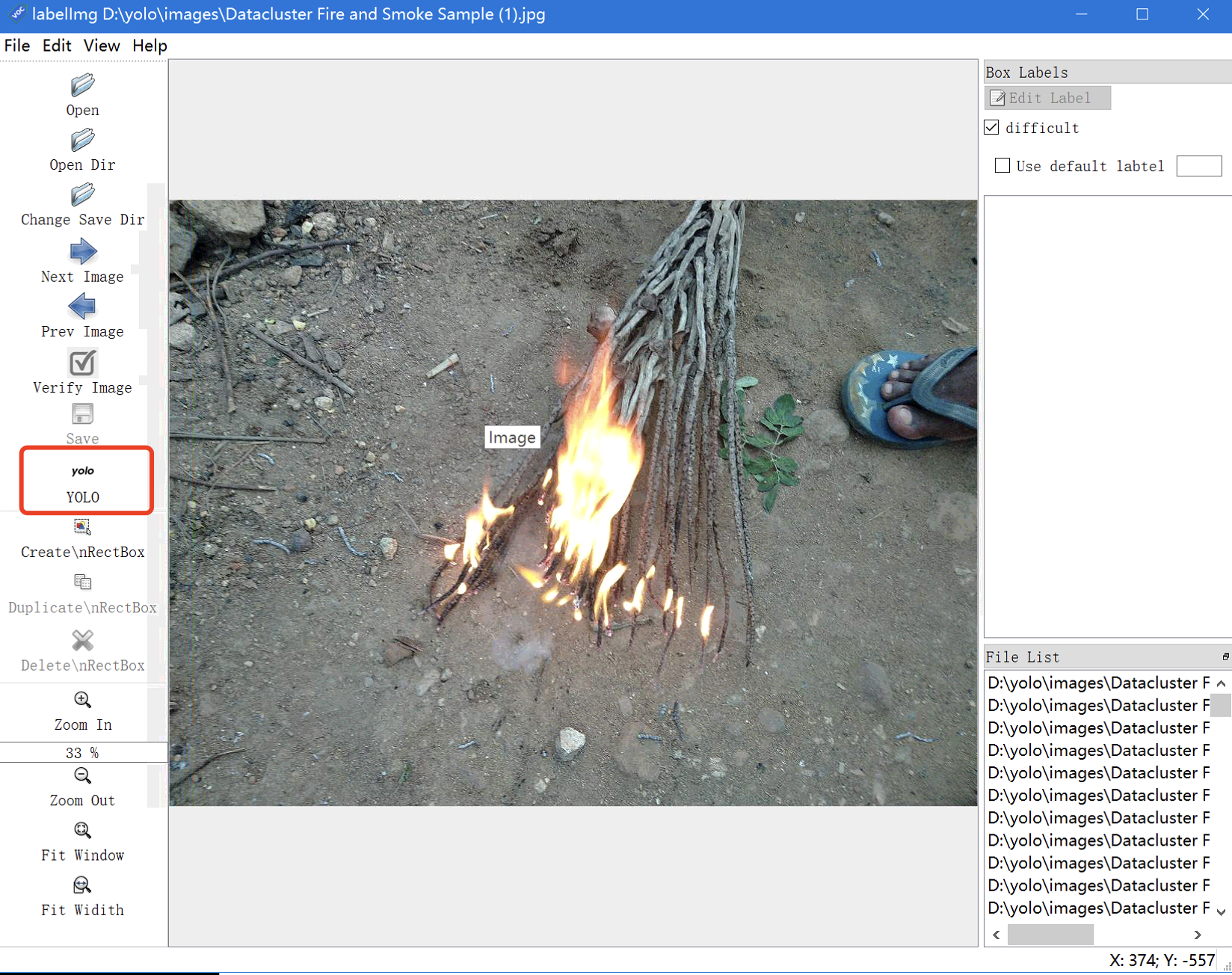
# 配置保存路径
设置标注文件保存路径:
点击菜单栏中的Change Save Dir按钮,选择你创建的labels文件夹。设置图片文件夹路径:
点击Open Dir按钮,选择你创建的images文件夹。切换为 YOLO 格式:
点击如下图所示位置,确保输出格式为 YOLO
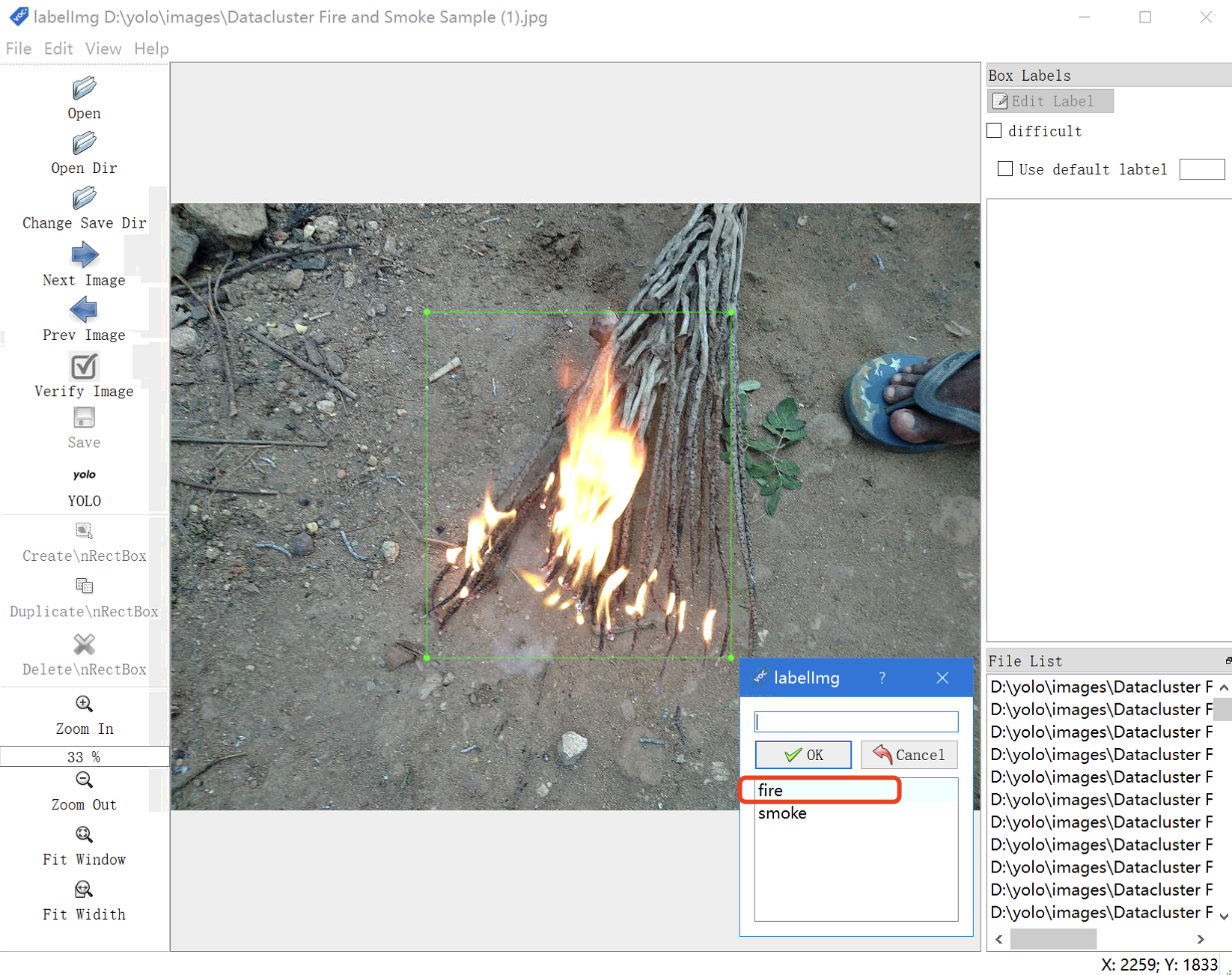
# 开始标注
- 快捷键
W或点击菜单栏Edit -> Create RectBox,开始绘制矩形框。 - 框住图像中需要识别的目标物体。
- 弹出类别选择框后,选择正确的类别并点击
OK。 - 使用快捷键
Ctrl + S保存当前标注。 - 快捷键
D跳转下一张图片。
如果图片中存在多个目标物体,可以分别框选并标注。
# 标注结果说明
每张图片标注完成后,都会在 labels 文件夹中生成一个同名的 .txt 文件,文件内容如下:
0 0.567 0.492 0.345 0.678
其中:
- 第一个数字是类别索引(0 表示火焰,1 表示烟雾)
- 后面四个数表示边界框的中心坐标和宽高(归一化值)
生产环境使用建议至少准备 1000 张以上标注数据。
下面是一些常用的labelImg的快捷键:
| 快捷键 | 功能 |
|---|---|
| Ctrl + Q | 退出软件 |
| Ctrl + O | 打开文件 |
| Ctrl + U | 打开目录 |
| Ctrl + R | 更改保存目录 |
| Ctrl + S | 保存 |
| Ctrl + L | 更改标注框的线条颜色 |
| Ctrl + J | 移动和编辑标注框 |
| Ctrl + D | 复制选中的框 |
| Ctrl + H | 隐藏所有标注框 |
| Ctrl + A | 显示所有标注框 |
| Ctrl + + | 放大图像 |
| Ctrl + - | 缩小图像 |
| Ctrl + = | 显示图像的原始大小 |
| Ctrl + F | 适应窗口大小 |
| Ctrl + Shift + O | 打开的文件夹中只显示 .xml 文件 |
| Ctrl + E | 编辑标签 |
| Ctrl + Shift + S | 将标注保存为其他格式 |
| Ctrl + Shift + F | 适应图像宽度 |
| Delete | 删除选中的标注框 |
| D | 显示下一张图片 |
| A | 显示上一张图片 |
| Space | 标记当前图片已标记 |
| W | 创建标注框 |
至此,已完成数据标注部分。接下来我们将进入数据集划分阶段。
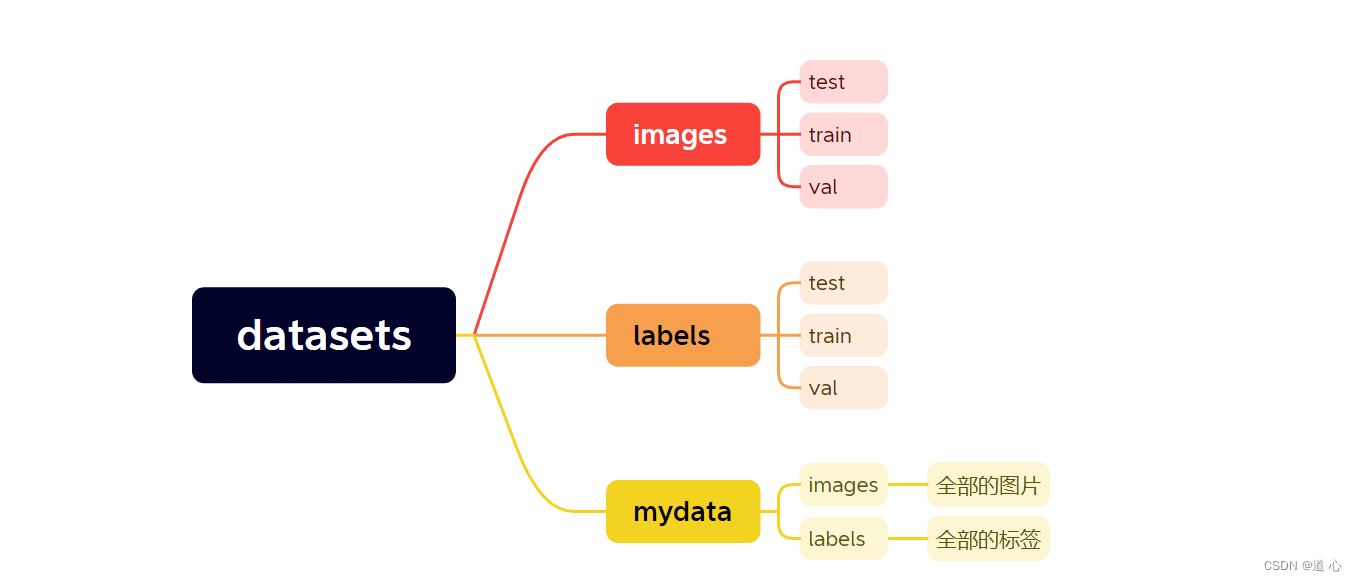
# 2. 划分数据集
在训练目标检测模型前,我们需要将数据集按比例划分为:
- 训练集(
train) - 验证集(
val) - 测试集(
test)
划分后的目录结构如下所示:
# 步骤一:准备划分脚本
将 split_yolo_dataset.py 脚本复制到 yolov12 项目根目录下。
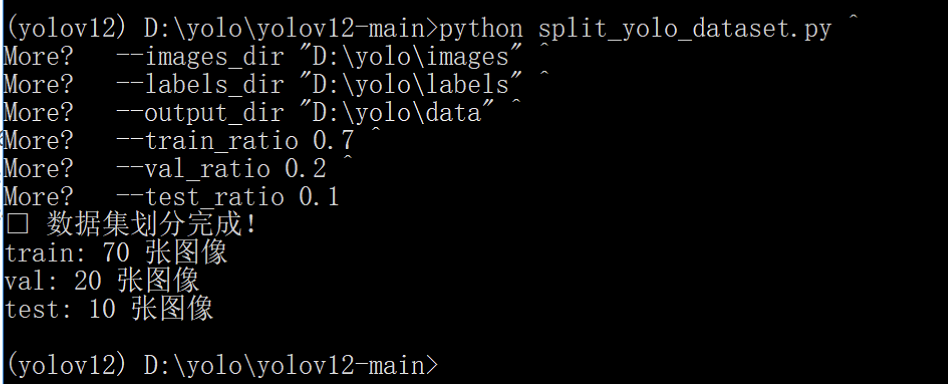
在 Anaconda Prompt 中,进入 yolov12 根目录,执行以下命令:
python split_yolo_dataset.py ^
--images_dir "D:\yolo\images" ^
--labels_dir "D:\yolo\labels" ^
--output_dir "D:\yolo\data" ^
--train_ratio 0.7 ^
--val_ratio 0.2 ^
--test_ratio 0.1
请根据自己的数据路径修改上述参数。
# 参数说明
| 参数名 | 示例值 | 描述 |
|---|---|---|
--images_dir | "D:\yolo\images" | 原始图像目录,包含所有需要划分的图片。 |
--labels_dir | "D:\yolo\labels" | 标签目录,通常为与图像同名的 .txt 文件,采用 YOLO 标注格式。 |
--output_dir | "D:\yolo\data" | 数据划分后的输出路径,会自动生成 train/, val/, test/ 子目录。 |
--train_ratio | 0.7 | 训练集比例,例如 0.7 表示占 70%。 |
--val_ratio | 0.2 | 验证集比例,例如 0.2 表示占 20%。 |
--test_ratio | 0.1 | 测试集比例,例如 0.1 表示占 10%。 |
⚠️ 注意:三个比例之和应等于 1。
output_dir目录请提前创建好,否则脚本可能报错。
执行成功如下图所示:
以下是你提供内容的优化版本,保留了原有结构和信息,但做了语言表达、格式统一和逻辑顺序上的优化,让内容更清晰易读、专业性更强:
# 3. 编写 data.yaml 配置文件
我们需要创建一个 data.yaml 文件,配置训练所需的路径和类别信息。请根据你的实际情况修改以下示例中的路径和类别名称:
train: D:/yolo/data/train/images # 训练集图像路径
val: D:/yolo/data/val/images # 验证集图像路径
test: D:/yolo/data/test/images # 测试集图像路径
nc: 2 # 类别数量
# 类别名称(顺序需与标注文件一致)
names: ['fire','smoke']
类别数量需要和类别名称里的数量一致
# 4. 开始训练模型
在 yolov12 根目录下创建一个新的 Python 文件 train.py,并粘贴以下代码:
yolov12.yaml和data.yaml都需要改为你自己的路径
本教程基于 yolov12.yaml 配置文件进行训练。默认将使用模型:yolov12n,若需使用更大模型(如 yolov12m 或 yolov12l),请将模型结构文件替换为相应的配置,例如:yolov12m.yaml。
import warnings
warnings.filterwarnings('ignore')
from ultralytics import YOLO
if __name__ == '__main__':
model = YOLO(model=r'D:\yolo\yolov12\ultralytics\cfg\models\v12\yolov12.yaml')
# model.load('yolo11n.pt') # 加载预训练权重,改进或者做对比实验时候不建议打开,因为用预训练模型整体精度没有很明显的提升
model.train(data=r'D:\yolo\data.yaml',
imgsz=640,
epochs=100,
batch=4,
workers=4,
device='cpu',
close_mosaic=10,
resume=False,
project='runs/train',
name='exp',
single_cls=False,
cache=False,
)
参数说明
| 参数名 | 示例值 | 说明 |
|---|---|---|
imgsz | 640 | 输入图像的尺寸,训练时会自动缩放到该大小 |
epochs | 100 | 训练轮数(整套数据训练的次数) |
batch | 4 | 每批训练的图片数量 |
workers | 4 | 数据加载的子进程数,提高数据预处理效率 |
device | 'cpu' | 训练设备,'0' 表示第一块GPU,'cpu' 表示使用 CPU |
close_mosaic | 10 | 训练后多少轮关闭 Mosaic 数据增强 |
resume | False | 是否断点续训 |
project | 'runs/train' | 训练结果保存的主目录 |
name | 'exp' | 当前实验的名称 |
single_cls | False | 是否视为单类别训练 |
cache | False | 是否将数据缓存到内存中,加快训练速度(需要较大内存) |
# 关于 epochs 和 batch 如何设置?
| 参数 | 建议设置(根据数据量和硬件) |
|---|---|
epochs | - 小数据集(几百张):建议 100~300 - 大数据集(上万张):建议 50~150 - 训练时间受限:先试 50 |
batch | 设置batch为CPU物理核心数的整数倍 |
执行训练命令
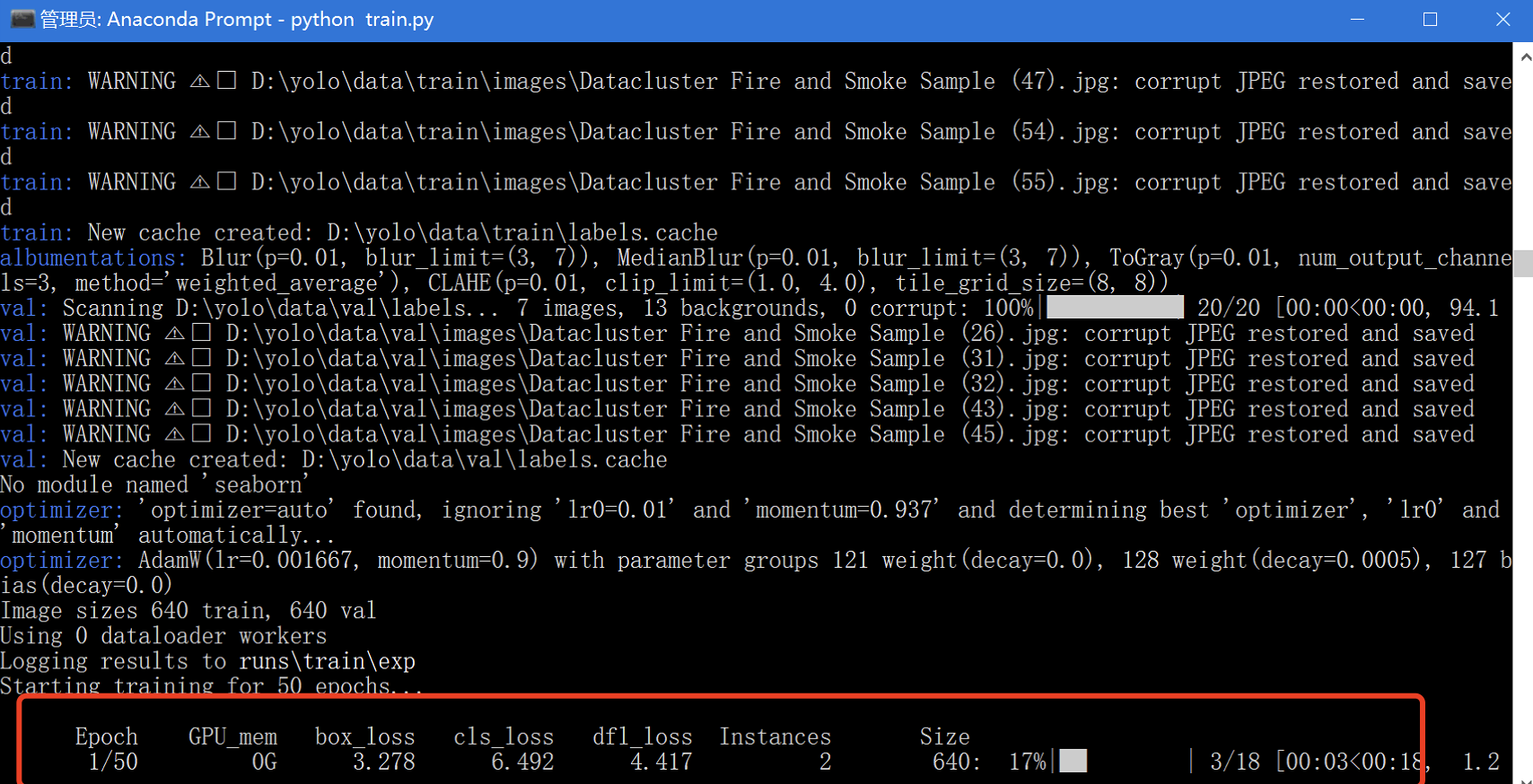
打开 Anaconda Prompt,切换到 yolov12 根目录,执行以下命令开始训练:
python train.py
如果看到类似以下输出,就说明训练已经开始:
训练完成后,你会看到如下提示:
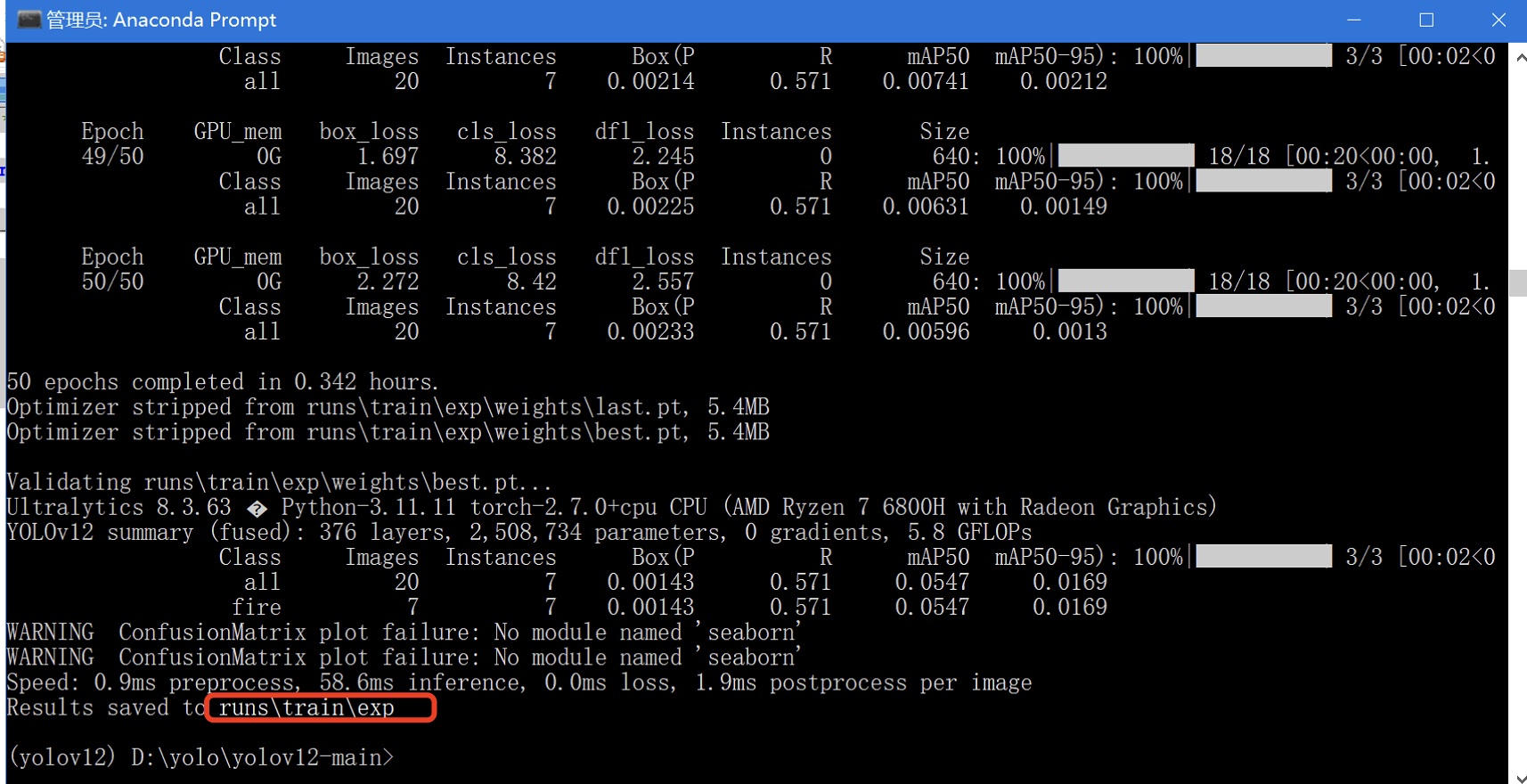
生成的模型文件如下:
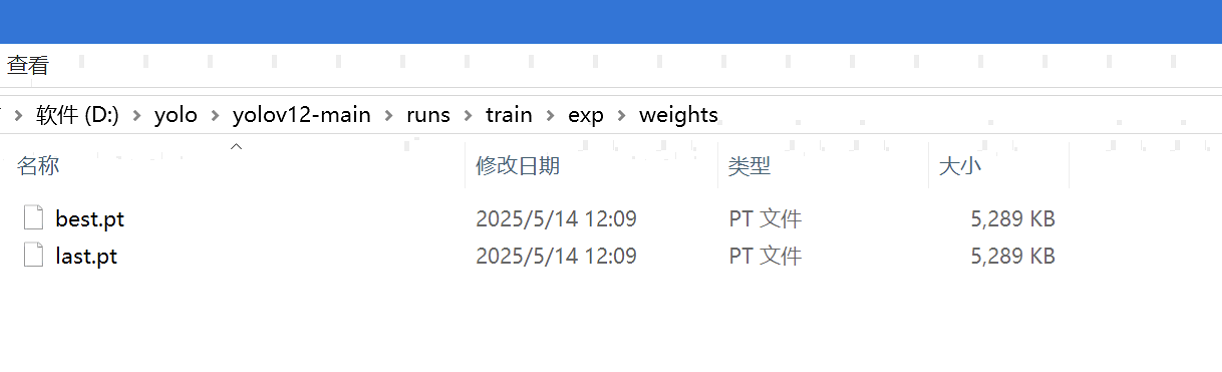
best.pt:模型在验证集上表现最好的权重文件last.pt:训练最后一轮保存的权重文件
# 5. 测试模型效果
新建 detect.py 文件,用于验证模型是否可用:
模型路径和测试图片路径需要修改为实际路径
# -*- coding: utf-8 -*-
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO(model=r'D:\yolo\yolov12\runs\train\exp3\weights\last.pt')
model.predict(source=r'D:\yolo\Fire and Smoke Dataset\Fire and Smoke Dataset\archive\Datacluster Fire and Smoke Sample\Datacluster Fire and Smoke Sample (60).jpg',
save=True,
show=False,
)
执行该脚本后,终端会输出预测完成的图片路径:

并在目录中保存预测结果图片:

至此,整个模型的训练与测试流程已基本完成。本教程作为入门级实践指南,旨在帮助读者熟悉模型开发的整体流程,不建议直接用于生产环境部署。如需应用于实际场景,仍需进一步优化,后续我们也将推出专门的模型调优教程。
特别说明:要获得理想的检测效果,通常需要至少上千张高质量、标注完整的训练图片。本教程所附的数据集仅用于演示流程,规模较小,因此模型效果有限,若无法准确检测属于正常现象。
我们也提供了一个已标注好的完整数据集(网盘中:yolo_fire_smoke_data.rar),可直接用于训练和验证。 数据集包含 3 个类别:fire、default、smoke。 若使用本数据集,需确保你的训练脚本和配置中类别数统一为 3 类。
# 6. 模型转换为 ONNX 格式
虽然模型已经训练结束,如果想要在Java环境中调用,需要将模型转换为Onnx格式
在 yolov12-main 根目录下创建一个新的 Python 文件 exportOnnx.py,并粘贴以下代码:
模型路径需要替换为实际路径
# -*- coding: utf-8 -*-
from ultralytics import YOLO
if __name__ == '__main__':
# Load a model
model = YOLO(model=r'C:\Users\Administrator\Downloads\best.pt')
result = model.export(format="onnx", imgsz=640, half=True) # or format="engine"
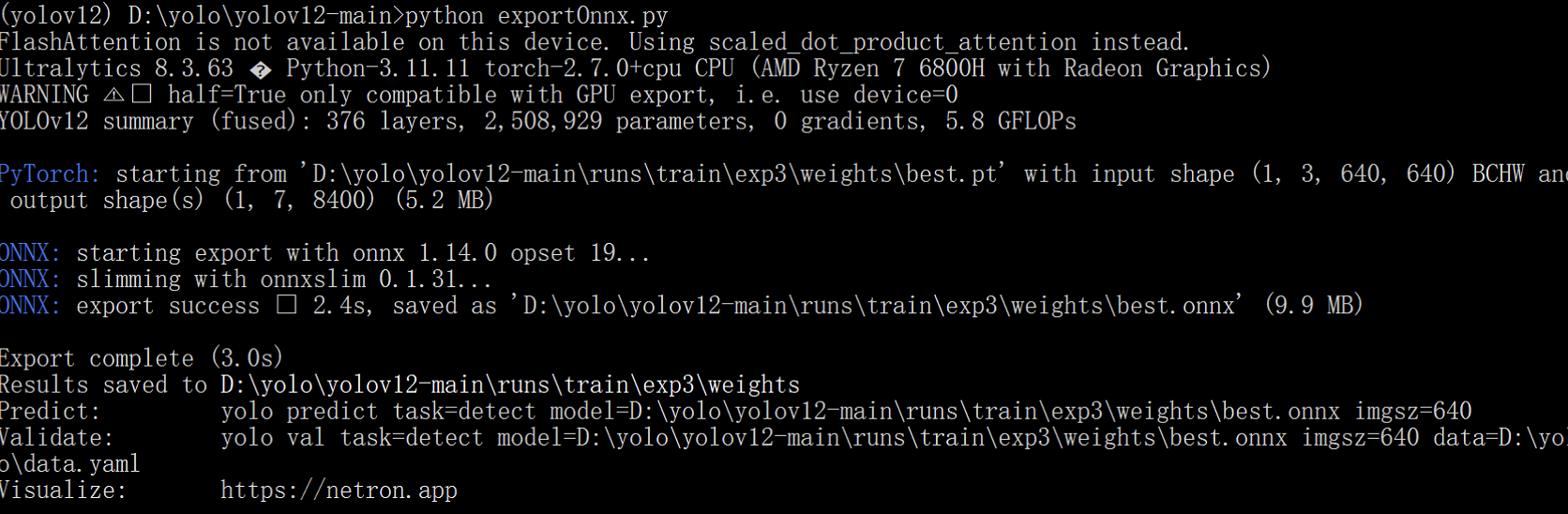
转换完毕,命令行窗口会打印出最终onnx格式的模型路径:saved as D:\yolo\yolov12-main\runs\train\exp3\weights\best.onnx