# OCR文字识别
# 简介
OCR(Optical Character Recognition,光学字符识别)是一种将图像中的文字内容自动识别并转换为可编辑、可搜索文本的技术。它广泛应用于文档数字化、票据识别、身份证扫描、车牌识别等场景。
OCR 的核心流程通常包括以下几个步骤:
图像预处理:对输入图像进行灰度化、去噪、二值化等处理,提高识别准确率。
文本检测:定位图像中出现文字的位置(即检测出文字框)。
方向分类:判断文字方向,确保后续识别按正确的方向进行(如是否旋转了90°)。
文字识别:将检测到的文字区域逐个识别为具体的字符或字符串。
后处理:对识别结果进行排序、去噪、拼接或结构化处理,提升可读性和准确性。
现代 OCR 系统往往结合深度学习算法(如 CRNN、Transformer、PP-OCR 等),在复杂场景下依然能保持较高的准确率,甚至能识别手写体、多语言、竖排文本等。
通用文字识别 |  | |
手写字识别 | 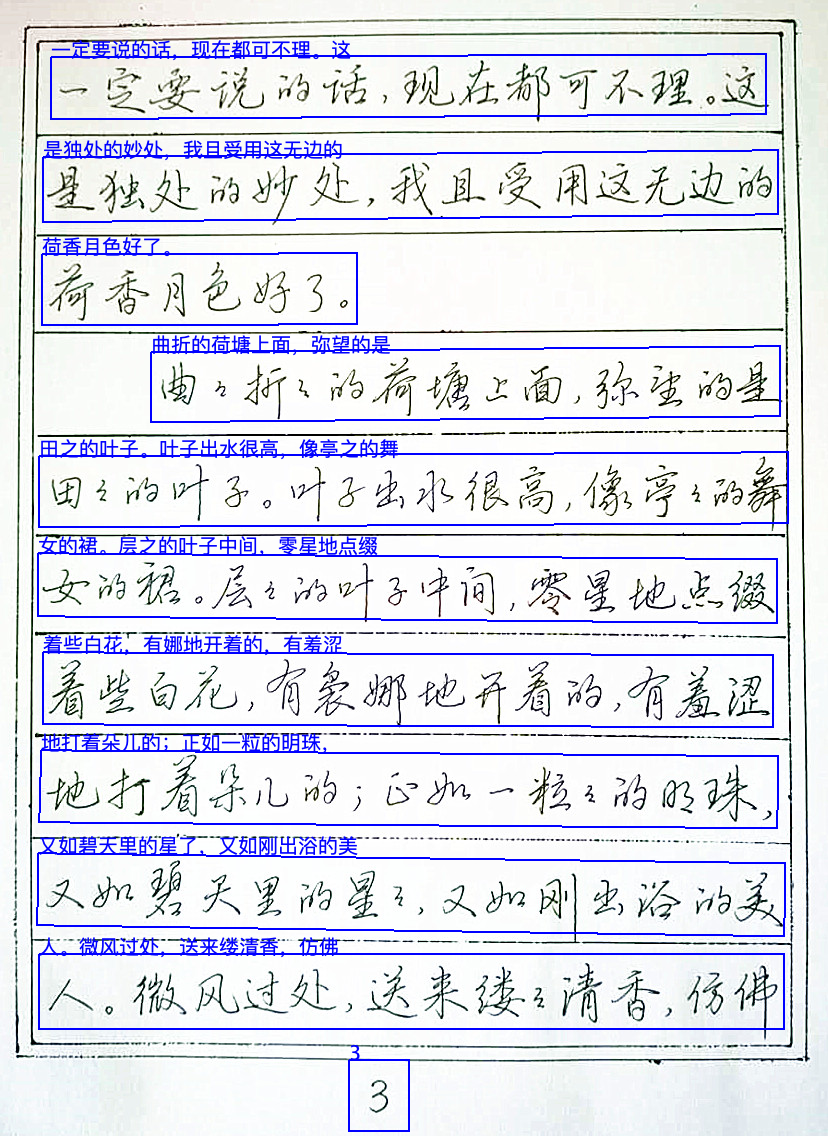 | |
票据识别 |  | |
多角度文本识别 |  | |
表格识别 |  | |
车牌识别 - 单层/双层检测- 车牌颜色识别 |  |  |
# 安装
# 1、环境要求
- Java 版本:JDK 8或更高版本
- 操作系统:Windows/Linux/MacOS
注意事项:
macos M系列芯片,目前不支持JDK8使用,最低请使用JDK11
# 2、Maven
在项目的 pom.xml 中添加以下依赖以及平台依赖库,详细引入方式参考 Maven 引入。如需引入全部功能,请使用 all 模块。
<dependency>
<groupId>cn.smartjavaai</groupId>
<artifactId>ocr</artifactId>
<version>1.1.1</version>
</dependency>
# 3、模型介绍及下载
# 文本检测模型
全部下载链接: https://pan.baidu.com/s/1tczxpxkdL_7h9WDT77RWCA?pwd=1234 提取码: 1234
| 模型名称 | 精度-检测 Hmean (%) | GPU 推理耗时(ms) 常规 / 高性能 | CPU 推理耗时(ms) 常规 / 高性能 | 模型大小 (MB) | 介绍 |
|---|---|---|---|---|---|
| PP-OCRv5_server_det | 83.8 | 89.55 / 70.19 | 371.65 / 371.65 | 84.3 | 服务端文本检测模型,精度更高,适合在性能较好的服务器上部署 |
| PP-OCRv5_mobile_det | 79.0 | 10.67 / 6.36 | 57.77 / 28.15 | 4.7 | 轻量文本检测模型,效率更高,适合在端侧设备部署 |
| PP-OCRv4_server_det | 69.2 | 127.82 / 98.87 | 585.95 / 489.77 | 109 | 服务端文本检测模型,精度更高,适合在性能较好的服务器上部署 |
| PP-OCRv4_mobile_det | 63.8 | 9.87 / 4.17 | 56.60 / 20.79 | 4.7 | 轻量文本检测模型,效率更高,适合在端侧设备部署 |
# 文本识别模型
| 模型名称 | 精度-Avg Accuracy (%) | GPU 推理耗时(ms) 常规 / 高性能 | CPU 推理耗时(ms) 常规 / 高性能 | 模型大小 (MB) | 介绍 |
|---|---|---|---|---|---|
| PP-OCRv5_server_rec | 86.38 | 8.45 / 2.36 | 122.69 / 122.69 | 81 | (服务端)致力于以单一模型高效、精准地支持简体中文、繁体中文、英文、日文四种主要语言,以及手写、竖版、拼音、生僻字等复杂文本场景的识别。在保持识别效果的同时,兼顾推理速度和模型鲁棒性,为各种场景下的文档理解提供高效、精准的技术支撑。 |
| PP-OCRv5_mobile_rec | 81.29 | 5.43 / 1.46 | 21.20 / 5.32 | 16 | (轻量)致力于以单一模型高效、精准地支持简体中文、繁体中文、英文、日文四种主要语言,以及手写、竖版、拼音、生僻字等复杂文本场景的识别。在保持识别效果的同时,兼顾推理速度和模型鲁棒性,为各种场景下的文档理解提供高效、精准的技术支撑。 |
| PP-OCRv4_server_rec | 85.19 | 8.75 / 2.49 | 36.93 / 36.93 | 173 | (服务端)推理精度高,可以部署在多种不同的服务器上 |
| PP-OCRv4_mobile_rec | 78.74 | 5.26 / 1.12 | 17.48 / 3.61 | 10.5 | (轻量) 效率更高,适合在端侧设备部署 |
# 文本方向分类模型(cls)
| 模型名称 | 精度- Top-1 Acc(%) | GPU推理耗时(ms) | CPU推理耗时 (ms) | 模型大小 (MB) | 介绍 |
|---|---|---|---|---|---|
| PP_LCNET_X0_25 | 98.85 | 2.16 / 0.41 | 2.37 / 0.73 | < 1 | (轻量)基于PP-LCNet_x0_25的文本行分类模型 |
| PP_LCNET_X1_0 | 99.42 | - / - | 2.98 / 2.98 | 6.5 | 基于PP-LCNet_x1_0的文本行分类模型 |
| ch_ppocr_mobile_v2.0_cls | < 1 | 原始分类器模型,对检测到的文本行文字角度分类 |
# 表格结构识别(Table Structure Recognition)
| 模型名称 | 精度(%) | GPU推理耗时(ms)[常规模式 / 高性能模式] | CPU推理耗时(ms)[常规模式 / 高性能模式] | 模型简介 | 模型开源网站 |
|---|---|---|---|---|---|
| SLANet | 59.52 | 23.96 / 21.75 | - / 43.12 | 该模型通过轻量级骨干 PP-LCNet、CSP-PAN 融合与 SLA Head 解码,有效提升表格结构识别的精度与速度。 | Github (opens new window) |
| SLANet_plus | 63.69 | 23.43 / 22.16 | - / 41.80 | (增强版)该模型通过轻量级骨干 PP-LCNet、CSP-PAN 融合与 SLA Head 解码,有效提升表格结构识别的精度与速度。 | Github (opens new window) |
OCR最佳实践:
提高识别速度的优化建议:
1、查看模型列表,优先选择高速、轻量级模型。
2、使用 GPU(高性能显卡)加速推理计算。
3、关闭方向矫正
# OCR文本检测
检测图像中的文本区域,仅返回文本框位置,不识别文字内容
获取OCR检测模型:
OcrDetModelConfig config = new OcrDetModelConfig();
config.setModelEnum(CommonDetModelEnum.PP_OCR_V5_MOBILE_DET_MODEL);
config.setDetModelPath("/PP-OCRv5_mobile_det_infer/PP-OCRv5_mobile_det_infer.onnx");
OcrCommonDetModel model = OcrModelFactory.getInstance().getDetModel(config);
OcrDetModelConfig参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| modelEnum | CommonDetModelEnum | 是 | 无 | OCR文本检测模型枚举 |
| detModelPath | String | 是 | 无 | 检测模型路径,需手动指定 |
| device | DeviceEnum | 否 | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 否 | 0 | gpu设备ID 当device为GPU时生效 |
| batchifier | String | 否 | 批量数据打包方式:stack,padding | |
| customParams | ConcurrentHashMap<String, Object> | 否 | 个性化配置 |
customParams个性化配置支持以下参数:
| 字段名称 | 字段类型 | 默认值 | 说明 |
|---|---|---|---|
| limit_side_len | int | 960 | 检测的图像边长限制 |
| max_candidates | int | 1000 | 输出的最大文本框数量 |
| min_size | int | 3 | 文本框最小尺寸阈值 |
| box_thresh | float | 0.6f | 文本框的分数阈值 |
注意事项:
模型必须位于单独文件夹中,否则可能导致加载失败。
文本检测方法
//推荐使用
List<OcrBox> detect(Image image);
//以下接口将在后续版本中移除
List<OcrBox> detect(String imagePath);
List<OcrBox> detect(BufferedImage image);
List<OcrBox> detect(byte[] imageData);
Image类说明:
所有接口中我们使用了一个Image类,用来表示图像,具体使用请查看Image类
OcrBox字段说明
- 返回并非json格式,仅用于字段讲解
[
{
"topLeft": { // 左上角坐标
"x": 838,
"y": 1069
},
"topRight": { // 右上角坐标
"x": 1149,
"y": 985
},
"bottomRight": { // 右下角坐标
"x": 1191,
"y": 1142
},
"bottomLeft": { // 左下角坐标
"x": 880,
"y": 1226
}
}
]
批量文本检测
批量文本检测,只支持分辨率一致的图片。
List<List<OcrBox>> batchDetect(List<BufferedImage> imageList)
List<List<OcrBox>> batchDetectDJLImage(List<Image> imageList)
检测并绘制文本框
void detectAndDraw(String imagePath, String outputPath);
Image detectAndDraw(Image image);
# OCR文本方向检测
- 检测每行文本的方向:支持返回四种可能的方向角度:0°, 90°, 180°, 270°,用于进一步识别处理。
- 检测流程:文本检测 -> 文本方向分类
注意事项:
模型必须位于单独文件夹中,否则可能导致加载失败。
获取OCR方向检测模型:
DirectionModelConfig directionModelConfig = new DirectionModelConfig();
directionModelConfig.setModelEnum(DirectionModelEnum.PP_LCNET_X0_25);
directionModelConfig.setModelPath("/PP-LCNet_x0_25_textline_ori_infer/PP-LCNet_x0_25_textline_ori_infer.onnx");
directionModelConfig.setDevice(device);
directionModelConfig.setTextDetModel(getDetectionModel());
return OcrModelFactory.getInstance().getDirectionModel(directionModelConfig);
DirectionModelConfig参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| modelEnum | DirectionModelEnum | 是 | 无 | 文本方向模型枚举 |
| modelPath | String | 是 | 无 | 文本方向检测模型路径,需手动指定 |
| textDetModel | OcrCommonDetModel | 是 | 无 | 文本检测模型 |
| detModelPath | String | 是 | 无 | 检测模型路径,需手动指定 |
| device | DeviceEnum | 否 | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 否 | 0 | gpu设备ID 当device为GPU时生效 |
| batchifier | String | 否 | 批量数据打包方式:stack,padding | |
| customParams | ConcurrentHashMap<String, Object> | 否 | 个性化配置 |
文本检测方法
//推荐使用
List<OcrItem> detect(Image image);
//以下接口将在后续版本中移除
List<OcrItem> detect(String imagePath);
List<OcrItem> detect(BufferedImage image);
List<OcrItem> detect(byte[] imageData);
OcrItem字段说明
- 返回并非json格式,仅用于字段讲解
[
{
"angle": "ANGLE_180", // 角度 枚举:AngleEnum
"ocrBox": {
"topLeft": { // 左上角坐标
"x": 838,
"y": 1069
},
"topRight": { // 右上角坐标
"x": 1149,
"y": 985
},
"bottomRight": { // 右下角坐标
"x": 1191,
"y": 1142
},
"bottomLeft": { // 左下角坐标
"x": 880,
"y": 1226
}
},
"score": 1 // 检测结果分数
}
]
检测并绘制检测结果
void detectAndDraw(String imagePath, String outputPath);
Image detectAndDraw(Image image);
# OCR文字识别
已集成PaddleOCR最新的-全场景文字识别模型PP-OCRv5:单模型支持五种文字类型和复杂手写体识别;整体识别精度相比上一代提升13个百分点。
支持简体中文、繁体中文、英文、日文四种主要语言,以及手写、竖版、拼音、生僻字
注意事项:
模型必须位于单独文件夹中,否则可能导致加载失败。
获取OCR文字识别模型:
OcrRecModelConfig recModelConfig = new OcrRecModelConfig();
recModelConfig.setRecModelEnum(CommonRecModelEnum.PP_OCR_V5_MOBILE_REC_MODEL);
recModelConfig.setRecModelPath("PP-OCRv5_mobile_rec_infer/PP-OCRv5_mobile_rec_infer.onnx");
recModelConfig.setDevice(device);
recModelConfig.setTextDetModel(getDetectionModel());
recModelConfig.setDirectionModel(getDirectionModel());
return OcrModelFactory.getInstance().getRecModel(recModelConfig);
OcrRecModelConfig参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| recModelEnum | CommonRecModelEnum | 是 | 无 | 文本识别模型枚举 |
| recModelPath | String | 是 | 无 | 文本识别模型路径,需手动指定 |
| textDetModel | OcrCommonDetModel | 是 | 无 | 文本检测模型 |
| directionModel | OcrDirectionModel | 是 | 无 | 文本方向模型 |
| device | DeviceEnum | 否 | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 否 | 0 | gpu设备ID 当device为GPU时生效 |
| batchifier | String | 否 | 批量数据打包方式:stack,padding | |
| customParams | ConcurrentHashMap<String, Object> | 否 | 个性化配置 |
文本识别方法
//推荐使用
OcrInfo recognize(Image image, OcrRecOptions options);
//以下接口将在后续版本中移除
OcrInfo recognize(String imagePath, OcrRecOptions options);
OcrInfo recognize(BufferedImage image, OcrRecOptions options);
OcrInfo recognize(byte[] imageData, OcrRecOptions options);
OcrRecOptions参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| enableDirectionCorrect | boolean | 是 | false | 是否进行文本方向矫正 |
| enableLineSplit | boolean | 是 | true | 是否进行结果分行 |
OcrInfo字段说明
fullText:识别得到的完整文本。每一行为一段识别结果,以换行符 \n 分隔;同一行中,多个检测框的文字以空格分隔。
lineList:按行组织的识别结果。每一行使用一个
List<OcrItem>表示,该列表包含该行中每个检测框对应的文字,便于结构化处理。ocrItemList: 当enableLineSplit = false; 则返回的lineList为空,ocrItemList 为识别结果列表
返回并非json格式,仅用于字段讲解
{
"fullText": "没有吃饱只有一个 \n烦恼 \n",
"lineList": [
[
{
"ocrBox": { // 左上角坐标
"topLeft": {
"x": 123,
"y": 605
},
"topRight": { // 右上角坐标
"x": 941,
"y": 359
},
"bottomRight": { // 右下角坐标
"x": 977,
"y": 481
},
"bottomLeft": { // 左下角坐标
"x": 161,
"y": 727
}
},
"text": "没有吃饱只有一个" // 文字
}
],
[
{
"ocrBox": {
"topLeft": {
"x": 123,
"y": 605
},
"topRight": {
"x": 941,
"y": 359
},
"bottomRight": {
"x": 977,
"y": 481
},
"bottomLeft": {
"x": 161,
"y": 727
}
},
"text": "烦恼"
}
]
]
}
批量文本识别
批量文本识别,只支持分辨率一致的图片。
List<OcrInfo> batchRecognizeDJLImage(List<Image> imageList, OcrRecOptions options)
List<OcrInfo> batchRecognize(List<BufferedImage> imageList, OcrRecOptions options)
识别并绘制识别结果
void recognizeAndDraw(String imagePath, String outputPath, OcrRecOptions options);
Image recognizeAndDraw(Image image, OcrRecOptions options);
# 表格识别
表格结构识别是表格识别系统中的重要组成部分,能够将不可编辑表格图片转换为可编辑的表格形式(例如html)。表格结构识别的目标是对表格的行、列和单元格位置进行识别
表格识别流程:
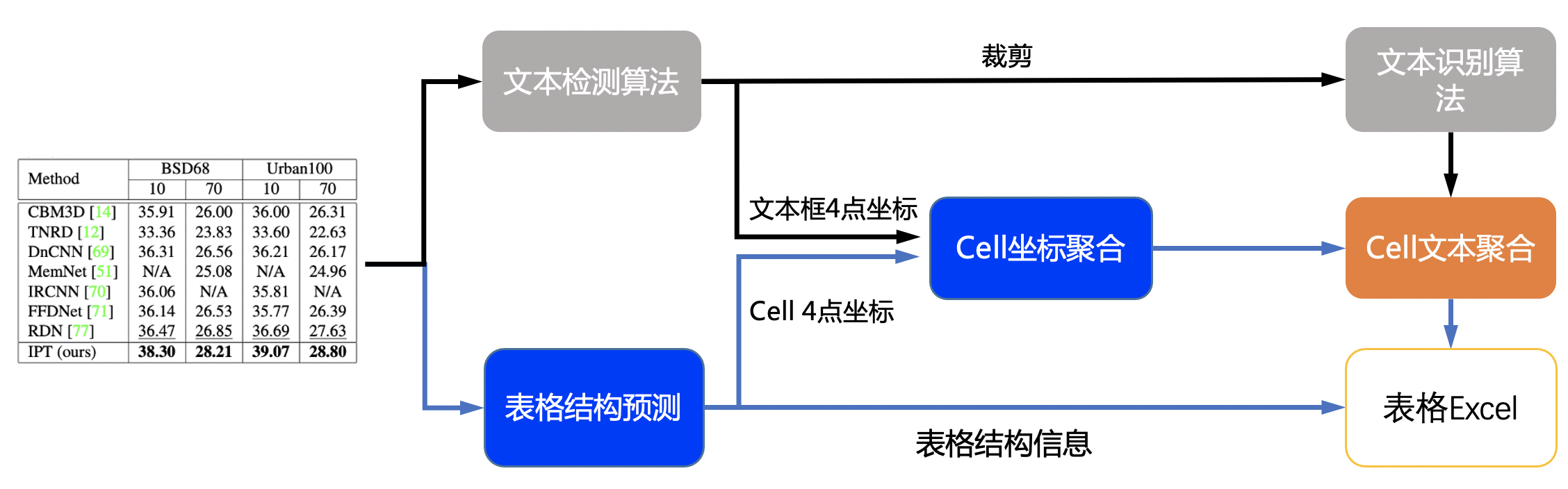
实际效果图:
获取表格结构识别模型:
TableStructureConfig config = new TableStructureConfig();
config.setModelEnum(TableStructureModelEnum.SLANET_PLUS);
config.setModelPath("/slanet-plus/slanet-plus.onnx");
config.setDevice(device);
TableStructureModel tableStructureModel = TableRecModelFactory.getInstance().getTableStructureModel(config);
TableStructureModel参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| modelEnum | TableStructureModelEnum | 是 | 无 | 模型枚举 |
| modelPath | String | 是 | 无 | 模型路径,需手动指定 |
| device | DeviceEnum | 否 | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 否 | 0 | gpu设备ID 当device为GPU时生效 |
| batchifier | String | 否 | 批量数据打包方式:stack,padding | |
| customParams | ConcurrentHashMap<String, Object> | 否 | 个性化配置 |
核心类说明:
| 类名 | 说明 |
|---|---|
| TableStructureModel | 表格结构识别模型,用于检测图像中的表格结构。 |
| OcrCommonDetModel | 文本检测模型,用于识别图像中的文本区域。 |
| OcrCommonRecModel | 文本识别模型,用于识别文本区域中的具体文字。 |
| OcrDirectionModel | 文本方向检测模型,用于识别文本是否旋转。 |
| TableRecognizer | 表格识别器,负责整合所有模型并执行表格识别流程。 |
构建表格识别器
TableRecognizer tableRecognizer = TableRecognizer.builder()
.withStructureModel(tableStructureModel)
.withTextDetModel(detModel)
.withDirectionModel(getDirectionModel())
.withTextRecModel(recModel).build();
其中除方向检测模型外,其他都是必须设置的模型,如果文本方向都是正向,无需设置方向检测模型
表格识别方法:
//推荐使用
R<TableStructureResult> recognize(Image image)
//以下接口将在后续版本中移除
R<TableStructureResult> recognize(String imagePath)
R<TableStructureResult> recognize(BufferedImage image)
R<TableStructureResult> recognize(byte[] imageData)
TableStructureResult字段说明
- 返回并非json格式,仅用于字段讲解
{
"ocrItemList": [
{
"ocrBox": { // 表格td检测框
"topLeft": {
"x": 1.2437801361083984,
"y": 3.537935495376587
},
"topRight": {
"x": 140.4019317626953,
"y": 3.537935495376587
},
"bottomRight": {
"x": 140.4019317626953,
"y": 90.6494369506836
},
"bottomLeft": {
"x": 1.2437801361083984,
"y": 90.6494369506836
}
},
"score": 0.9998747
},
{
"ocrBox": {
"topLeft": {
"x": 128.6870574951172,
"y": 4.578607082366943
},
"topRight": {
"x": 263.6147155761719,
"y": 4.578607082366943
},
"bottomRight": {
"x": 263.6147155761719,
"y": 88.69718170166016
},
"bottomLeft": {
"x": 128.6870574951172,
"y": 88.69718170166016
}
},
"score": 0.99999917
}
],
"tableTagList": [ //表格标签
"<html>",
"<body>",
"<table>",
"<tr>",
"<td></td>",
"<td></td>",
"</tr>",
"<tr>",
"<td></td>",
"<td></td>",
"</tr>",
"<tr>",
"<td",
" colspan\u003d\"2\"",
">",
"</td>",
"</tr>",
"</table>",
"</body>",
"</html>"
],
"html": "<style>\ntable { border-collapse: collapse; }\ntd, th, table { border: 1px solid black; padding: 5px; }\n</style>\n<html><body><table><tr><td>姓名</td><td>年龄</td></tr><tr><td>张三</td><td>18</td></tr><tr><td colspan\u003d\"2\"></td></tr></table></body></html>"
}
也可以通过如下方法绘制表格结构识别结果:
public Image drawTable(TableStructureResult tableStructureResult, Image image)
public void drawTable(TableStructureResult tableStructureResult, BufferedImage image, String savePath)
也可以将html内容导出excel文件:
public void exportExcel(String html, String savePath)
注意事项:
1、目前表格识别仅支持简单表格,复杂表格可能会识别不准确
2、如果导出excel报错,可以通过drawTable导出表格结构识别结果,查看表格结构是否识别正确
# 车牌检测
车牌检测是计算机视觉中的一项技术,用于从图像或视频中自动定位车辆的车牌区域,支持识别单层和双层车牌,为后续的车牌字符识别提供精准输入

支持的模型如下:
| 模型名称 | 模型简介 | 模型开源网站 |
|---|---|---|
| YOLOV5 | 基于YOLOV5训练,支持12种中文车牌 | Github (opens new window) |
| yolov7-lite-t | (超小型模型)YOLOv7-Lite 架构的轻量级车牌检测模型 | Github (opens new window) |
| yolov7-lite-s | YOLOv7-Lite 架构的轻量级车牌检测模型 | Github (opens new window) |
获取车牌检测模型:
PlateDetModelConfig config = new PlateDetModelConfig();
config.setModelEnum(PlateDetModelEnum.YOLOV5);
config.setModelPath("/model/plate/yolov5_plate_detect.onnx");
config.setDevice(device);
PlateDetModel plateDetModel = PlateModelFactory.getInstance().getDetModel(config);
PlateDetModelConfig参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| modelEnum | CommonDetModelEnum | 是 | 无 | 车牌检测模型枚举 |
| modelPath | String | 是 | 无 | 检测模型路径,需手动指定 |
| confidenceThreshold | float | 否 | 0.3f | 置信度阈值 |
| iouThreshold | float | 否 | 0.5f | iou阈值 |
| topK | int | 否 | 100 | 检测结果数量 |
| device | DeviceEnum | 否 | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 否 | 0 | gpu设备ID 当device为GPU时生效 |
| customParams | ConcurrentHashMap<String, Object> | 否 | 个性化配置 |
注意事项:
模型必须位于单独文件夹中,否则可能导致加载失败。
文本检测方法
//推荐使用
R<List<PlateInfo>> detect(Image image);
//以下接口将在后续版本中移除
R<List<PlateInfo>> detect(String imagePath);
R<List<PlateInfo>> detect(BufferedImage image);
R<List<PlateInfo>> detect(byte[] imageData);
R<List<PlateInfo>> detect(InputStream inputStream);
R<List<PlateInfo>> detectBase64(String base64Image);
检测并绘制检测结果
void detectAndDraw(String imagePath, String outputPath);
Image detectAndDraw(Image image);
PlateInfo字段说明
- 返回并非json格式,仅用于字段讲解
[
{
"plateType": "SINGLE", //车牌类型:SINGLE-单层,DOUBLE-双层
"detectionRectangle": { //车牌位置信息
"x": 424,
"y": 298,
"width": 243,
"height": 130
},
"box": { // 车牌4点坐标
"topLeft": {
"x": 424.96429443359375,
"y": 351.9092102050781
},
"topRight": {
"x": 646.1655883789062,
"y": 297.97735595703125
},
"bottomRight": {
"x": 669.95361328125,
"y": 376.01025390625
},
"bottomLeft": {
"x": 445.5194091796875,
"y": 427.5689392089844
}
},
"score": 0.9076154
}
]
# 车牌识别
车牌识别(License Plate Recognition, 简称 LPR)是一种基于计算机视觉的技术,用于自动检测图像或视频中的车牌位置,并识别车牌上的字符信息,通常包括省份简称、字母和数字等内容
车牌识别流程:
车牌检测 -> 车牌矫正 -> 车牌识别
支持的模型如下:
| 模型名称 | 模型简介 | 模型开源网站 |
|---|---|---|
| PLATE_REC_CRNN | CRNN中文字符识别 | Github (opens new window) |
获取车牌识别模型:
PlateRecModelConfig recModelConfig = new PlateRecModelConfig();
recModelConfig.setModelEnum(PlateRecModelEnum.PLATE_REC_CRNN);
recModelConfig.setModelPath("/model/plate/plate_rec_color.onnx");
recModelConfig.setPlateDetModel(getPlateDetModel());
return PlateModelFactory.getInstance().getRecModel(recModelConfig);
PlateDetModelConfig参数说明
| 字段名称 | 字段类型 | 必选 | 默认值 | 说明 |
|---|---|---|---|---|
| modelEnum | CommonDetModelEnum | 是 | 无 | 车牌识别模型枚举 |
| modelPath | String | 是 | 无 | 检测模型路径,需手动指定 |
| plateDetModel | PlateDetModel | 是 | 无 | 车牌检查模型 |
| device | DeviceEnum | 否 | CPU | 指定运行设备,支持 CPU/GPU |
| gpuId | int | 否 | 0 | gpu设备ID 当device为GPU时生效 |
| customParams | ConcurrentHashMap<String, Object> | 否 | 个性化配置 |
注意事项:
模型必须位于单独文件夹中,否则可能导致加载失败。
车牌识别方法
//推荐使用
R<List<PlateInfo>> recognize(Image image);
//以下接口将在后续版本中移除
R<List<PlateInfo>> recognize(String imagePath);
R<List<PlateInfo>> recognize(BufferedImage image);
R<List<PlateInfo>> recognize(byte[] imageData);
R<List<PlateInfo>> recognize(InputStream inputStream);
R<List<PlateInfo>> recognizeBase64(String base64Image);
车牌识别方法(裁剪后图片)
R<List<PlateInfo>> recognizeCropped(Image image);
识别并绘制识别结果
void recognizeAndDraw(String imagePath, String outputPath);
Image recognizeAndDraw(Image image);
PlateInfo字段说明
- 返回并非json格式,仅用于字段讲解
车牌颜色支持:黑色, 蓝色, 绿色, 白色, 黄色
[
{
"plateType": "SINGLE", //车牌类型:SINGLE-单层,DOUBLE-双层
"plateNumber": "川A8H458", //车号
"plateColor": "蓝色", //车牌颜色
"detectionRectangle": {
"x": 424,
"y": 298,
"width": 243,
"height": 130
},
"box": {
"topLeft": {
"x": 424.96429443359375,
"y": 351.9092102050781
},
"topRight": {
"x": 646.1655883789062,
"y": 297.97735595703125
},
"bottomRight": {
"x": 669.95361328125,
"y": 376.01025390625
},
"bottomLeft": {
"x": 445.5194091796875,
"y": 427.5689392089844
}
},
"score": 0.9076154
}
]